Variational Quantum Eigensolver (VQE)
Această lecție prezintă variational quantum eigensolver, explică importanța sa ca algoritm de bază în calculul cuantic și explorează punctele forte și slabe ale acestuia. VQE în sine, fără metode de augmentare, probabil că nu va fi suficient pentru calculele cuantice la scară modernă de utilitate. Cu toate acestea, este important ca metodă hibridă clasică-cuantică arhetipală și constituie o fundație importantă pe care sunt construiți mulți algoritmi mai avansați.
Acest videoclip oferă o prezentare generală a VQE și a factorilor care îi afectează eficiența. Textul de mai jos adaugă mai multe detalii și implementează VQE folosind Qiskit.
1. Ce este VQE?
Variational quantum eigensolver este un algoritm care utilizează calculul clasic și cel cuantic împreună pentru a îndeplini o sarcină. Există patru componente principale ale unui calcul VQE:
- Un operator: Adesea un Hamiltonian, pe care îl vom numi , ce descrie o proprietate a sistemului tău pe care dorești să o optimizezi. O altă modalitate de a spune asta este că tu cauți vectorul propriu al acestui operator care corespunde valorii proprii minime. Acel vector propriu este adesea numit „starea de bază" (ground state).
- Un „ansatz" (un cuvânt german cu sensul „abordare"): acesta este un circuit cuantic care pregătește o stare cuantică ce aproximează vectorul propriu căutat. De fapt, ansatz-ul este o familie de circuite cuantice, deoarece unele dintre Gate-urile din ansatz sunt parametrizate, adică li se furnizează un parametru pe care îl putem varia. Această familie de circuite cuantice poate pregăti o familie de stări cuantice care aproximează starea de bază.
- Un Estimator: un mijloc de estimare a valorii de așteptare a operatorului pe starea cuantică variaționară curentă. Uneori, ce ne interesează cu adevărat este chiar această valoare de așteptare, pe care o numim funcție de cost. Alteori, ne interesează o funcție mai complicată care poate fi totuși scrisă pornind de la una sau mai multe valori de așteptare.
- Un optimizator clasic: un algoritm care variază parametrii pentru a încerca să minimizeze funcția de cost.
Să analizăm fiecare dintre aceste componente în mai multă profunzime.
1.1 Operatorul (Hamiltonianul)
La baza unei probleme VQE se află un operator care descrie un sistem de interes. Vom presupune că valoarea proprie minimă și vectorul propriu corespunzător al acestui operator sunt utile pentru un scop științific sau de afaceri. Exemple ar putea include un Hamiltonian chimic care descrie o moleculă, astfel încât valoarea proprie minimă a operatorului corespunde energiei stării de bază a moleculei, iar starea proprie corespunzătoare descrie geometria sau configurația electronică a moleculei. Sau operatorul ar putea descrie costul unui anumit proces de optimizat, iar stările proprii ar putea corespunde rutelor sau practicilor. În unele domenii, cum ar fi fizica, un „Hamiltonian" se referă aproape întotdeauna la un operator ce descrie energia unui sistem fizic. Dar în calculul cuantic, este obișnuit să vezi operatori cuantici care descriu o problemă de afaceri sau logistică și care sunt, de asemenea, numiți „Hamiltonian". Vom adopta această convenție aici.

Maparea unei probleme fizice sau de optimizare pe qubiți este, de obicei, o sarcină non-trivială, dar acele detalii nu sunt obiectul acestui curs. O discuție generală despre maparea unei probleme pe un operator cuantic poate fi găsită în Quantum computing in practice. O privire mai detaliată asupra mapării problemelor de chimie în operatori cuantici poate fi găsită în Quantum Chemistry with VQE.
În scopul acestui curs, vom presupune că forma Hamiltonianului este cunoscută. De exemplu, un Hamiltonian pentru o moleculă simplă de hidrogen (sub anumite ipoteze de spațiu activ și folosind mapper-ul Jordan-Wigner) este:
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy
from qiskit.quantum_info import SparsePauliOp
hamiltonian = SparsePauliOp(
[
"IIII",
"IIIZ",
"IZII",
"IIZI",
"ZIII",
"IZIZ",
"IIZZ",
"ZIIZ",
"IZZI",
"ZZII",
"ZIZI",
"YYYY",
"XXYY",
"YYXX",
"XXXX",
],
coeffs=[
-0.09820182 + 0.0j,
-0.1740751 + 0.0j,
-0.1740751 + 0.0j,
0.2242933 + 0.0j,
0.2242933 + 0.0j,
0.16891402 + 0.0j,
0.1210099 + 0.0j,
0.16631441 + 0.0j,
0.16631441 + 0.0j,
0.1210099 + 0.0j,
0.17504456 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
],
)
Observă că în Hamiltonianul de mai sus există termeni precum ZZII și YYYY care nu comutează între ei. Adică, pentru a evalua ZZII, ar trebui să măsurăm operatorul Pauli Z pe qubit-ul 3 (printre alte măsurători). Dar pentru a evalua YYYY, trebuie să măsurăm operatorul Pauli Y pe același qubit, qubit-ul 3. Există o relație de incertitudine între operatorii Y și Z pe același qubit; nu putem măsura ambii operatori în același timp. Vom reveni la acest punct mai jos și, de fapt, pe tot parcursul cursului.
Hamiltonianul de mai sus este un operator matricial de . Diagonalizarea operatorului pentru a găsi valoarea proprie minimă nu este dificilă.
import numpy as np
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues), "hartrees")
The ground state energy is -1.1459778447627311 hartrees
Solverele clasice de valori proprii brute nu pot scala pentru a descrie energiile sau geometriile sistemelor foarte mari de atomi, cum ar fi medicamentele sau proteinele. VQE este una dintre primele încercări de a utiliza calculul cuantic în această problemă.
Vom întâlni Hamiltonieni în această lecție mult mai mari decât cel de mai sus. Dar ar fi risipitor să împingem limitele a ceea ce poate face VQE, înainte de a introduce câteva dintre instrumentele mai avansate care pot augmenta sau înlocui VQE, mai târziu în acest curs.
1.2 Ansatz
Cuvântul „ansatz" este german și înseamnă „abordare". Pluralul corect în germană este „ansätze", deși adesea se vede „ansatzes" sau „ansatze". În contextul VQE, un ansatz este circuit-ul cuantic pe care îl folosești pentru a crea o funcție de undă multi-qubiți care aproximează cel mai bine starea de bază a sistemului studiat și care, astfel, produce cea mai mică valoare de așteptare a operatorului tău. Acest circuit cuantic va conține parametri variaționali (adesea reuniți în vectorul de variabile ).

Se alege un set inițial de valori ale parametrilor variaționali. Vom numi operația unitară a ansatz-ului pe Circuit . În mod implicit, toți qubiții din calculatoarele cuantice IBM® sunt inițializați în starea . Când Circuit-ul rulează, starea qubiților va fi
Dacă tot ce am nevoie ar fi energia minimă (folosind limbajul sistemelor fizice), am putea estima aceasta simplu măsurând energia de multe ori și luând minimul. Dar de obicei vrem și configurația care produce acea energie minimă sau valoare proprie. Deci, pasul următor este estimarea valorii de așteptare a Hamiltonianului, care se realizează prin măsurători cuantice. Există mult de spus despre asta. Dar putem înțelege calitativ acest proces observând că probabilitatea de a măsura o energie (din nou, folosind limbajul sistemelor fizice) este legată de valoarea de așteptare prin:
Probabilitatea este, de asemenea, legată de suprapunerea dintre starea proprie și starea curentă a sistemului :
Astfel, făcând multe măsurători ale operatorilor Pauli care alcătuiesc Hamiltonianul nostru, putem estima valoarea de așteptare a Hamiltonianului în starea curentă a sistemului . Pasul următor este să variezi parametrii și să te apropii mai mult de starea de bază (ground state) a sistemului cu cea mai mică energie. Datorită parametrilor variaționali din ansatz, uneori acesta este denumit forma variaționară.
Înainte de a trece la acel proces variațional, observă că este adesea util să pornești starea dintr-o stare de „bun puncte de plecare". Poate cunoști suficient de bine sistemul pentru a face o presupunere inițială mai bună decât . De exemplu, este obișnuit să inițializezi qubiții în starea Hartree-Fock în aplicațiile chimice. Această presupunere de start care nu conține niciun parametru variațional se numește stare de referință. Să numim Circuit-ul cuantic folosit pentru a crea starea de referință . Ori de câte ori devine important să distingem starea de referință de restul ansatz-ului, folosim: Echivalent,
1.3 Estimator
Avem nevoie de o modalitate de a estima valoarea de așteptare a Hamiltonianului nostru într-o anumită stare variaționară . Dacă am putea măsura direct întregul operator , aceasta ar fi la fel de simplă ca și efectuarea multor (să spunem ) măsurători și calcularea mediei valorilor măsurate:
Aici, simbolul ne amintește că această valoare de așteptare ar fi precis corectă doar în limita . Dar cu mii de măsurători efectuate pe un circuit, eroarea de eșantionare a valorii de așteptare este destul de mică. Există alte considerații, cum ar fi zgomotul, care devin o problemă pentru calcule foarte precise.
Cu toate acestea, în general nu este posibil să măsori dintr-odată. poate conține mai mulți operatori Pauli X, Y și Z care nu comutează. Deci, Hamiltonianul trebuie împărțit în grupuri de operatori ce pot fi măsurați simultan, fiecare astfel de grup trebuie estimat separat, iar rezultatele combinate pentru a obține o valoare de așteptare. Vom revizui aceasta în mai mare detaliu în lecția următoare, când discutăm scalarea abordărilor clasice și cuantice. Această complexitate în măsurare este unul dintre motivele pentru care avem nevoie de cod foarte eficient pentru a efectua o astfel de estimare. În această lecție și mai departe, vom folosi primitivul Qiskit Runtime Estimator în acest scop.
1.4 Optimizatorii clasici
Un optimizator clasic este orice algoritm clasic conceput pentru a găsi extremele unei funcții țintă (de obicei un minim). Ei caută în spațiul parametrilor posibili un set care minimizează o funcție de interes. Pot fi clasificate în linii mari în metode bazate pe gradient, care utilizează informații despre gradient, și metode fără gradient, care funcționează ca optimizatori de tip cutie neagră. Alegerea optimizatorului clasic poate afecta semnificativ performanța unui algoritm, mai ales în prezența zgomotului în hardware-ul cuantic. Optimizatorii populari în acest domeniu includ Adam, AMSGrad și SPSA, care au arătat rezultate promițătoare în medii zgomotoase. Optimizatorii mai tradiționali includ COBYLA și SLSQP.
Un flux de lucru comun (demonstrat în Secțiunea 3.3) este să folosești unul dintre acești algoritmi ca metodă într-un minimizator precum funcția minimize din scipy. Aceasta primește ca argumente:
- O funcție de minimizat. Aceasta este adesea valoarea de așteptare a energiei. Dar în general sunt numite „funcții de cost".
- Un set de parametri de la care să înceapă căutarea. Adesea numite sau .
- Argumente, inclusiv argumentele funcției de cost. În calculul cuantic cu Qiskit, aceste argumente vor include ansatz-ul, Hamiltonianul și primitivul Estimator, discutat mai mult în subsecțiunea următoare.
- O „metodă" de minimizare. Aceasta se referă la algoritmul specific utilizat pentru a căuta spațiul parametrilor. Aici am specifica, de exemplu, COBYLA sau SLSQP.
- Opțiuni. Opțiunile disponibile pot diferi în funcție de metodă. Dar un exemplu pe care practic toate metodele l-ar include este numărul maxim de iterații ale optimizatorului înainte de a încheia căutarea: 'maxiter'.

La fiecare pas iterativ, valoarea de așteptare a Hamiltonianului este estimată prin multe măsurători. Această energie estimată este returnată de funcția de cost, iar minimizatorul actualizează informațiile pe care le are despre peisajul energetic. Ce face exact optimizatorul pentru a alege pasul următor variază de la o metodă la alta. Unele folosesc gradienți și selectează direcția de descărcere cea mai abruptă. Altele pot ține cont de zgomot și pot cere ca costul să scadă cu o marjă mare înainte de a accepta că energia adevărată scade în acea direcție.
# Example syntax for minimization
# from scipy.optimize import minimize
# res = minimize(cost_func, x0, args=(ansatz, hamiltonian, estimator), method="cobyla",
# options={'maxiter': 200})
1.5 Principiul variațional
În acest context, principiul variațional este foarte important; el afirmă că nicio funcție de undă variaționară nu poate produce o valoare de așteptare a energiei (sau a costului) mai mică decât cea produsă de funcția de undă a stării de bază. Matematic,
Acest lucru este ușor de verificat dacă observăm că setul tuturor stărilor proprii ale lui formează o bază completă pentru spațiul Hilbert. Cu alte cuvinte, orice stare și în special poate fi scrisă ca o sumă ponderată (normalizată) a acestor stări proprii ale lui :
unde sunt constante de determinat, și . Lăsăm aceasta ca exercițiu pentru cititor. Dar observă implicația: starea variaționară care produce cea mai mică valoare de așteptare a energiei este cea mai bună estimare a stării de bază reale.
Verifică-ți înțelegerea
Verifică matematic că pentru orice stare variaționară .
Răspuns
Folosind expansiunea dată a stării variaționare în termeni de stări proprii ale energiei,
putem scrie valoarea de așteptare a energiei variaționare ca
Pentru toți coeficienții . Deci putem scrie
2. Comparație cu fluxul de lucru clasic
Să presupunem că suntem interesați de o matrice cu N rânduri și N coloane. Presupune că matricea ta este atât de mare încât diagonalizarea exactă nu este o opțiune. Presupune, de asemenea, că știi suficient despre problema ta pentru a face câteva presupuneri despre structura generală a stării proprii țintă și vrei să explorezi stări similare presupunerii tale inițiale pentru a vedea dacă costul/energia ta poate fi redusă în continuare. Aceasta este o abordare variaționară și este una dintre metodele folosite atunci când diagonalizarea exactă nu este o opțiune.
2.1 Fluxul de lucru clasic
Folosind un calculator clasic, aceasta ar funcționa astfel:
- Fă o stare de presupunere, cu unii parametri pe care îi vei varia: . Deși această presupunere inițială ar putea fi aleatorie, nu este recomandat. Vrem să folosim cunoașterea problemei la îndemână pentru a ne adapta presupunerea cât mai mult posibil.
- Calculează valoarea de așteptare a operatorului cu sistemul în acea stare:
- Modifică parametrii variaționali și repetă: .
- Folosește informațiile acumulate despre peisajul stărilor posibile din subspațiul tău variațional pentru a face presupuneri din ce în ce mai bune și a te apropia de starea țintă. Principiul variațional garantează că starea noastră variaționară nu poate produce o valoare proprie mai mică decât cea a stării de bază țintă. Deci cu cât valoarea de așteptare este mai mică, cu atât aproximarea noastră a stării de bază este mai bună:
Să examinăm dificultatea fiecărui pas în această abordare. Setarea sau actualizarea parametrilor este computațional ușoară; dificultatea acolo constă în selectarea unor parametri inițiali utili, motivați fizic. Folosirea informațiilor acumulate din iterațiile anterioare pentru a actualiza parametrii în astfel de mod încât să te apropii de starea de bază este non-trivială. Dar există algoritmi de optimizare clasici care fac asta destul de eficient. Această optimizare clasică este costisitoare doar pentru că poate necesita multe iterații; în cel mai rău caz, numărul de iterații poate scala exponențial cu N. Cel mai costisitor pas computațional individual este aproape sigur calcularea valorii de așteptare a matricei folosind o stare dată :
Matricea trebuie să acționeze pe vectorul cu elemente, ceea ce corespunde: operații de multiplicare în cel mai rău caz. Aceasta trebuie făcută la fiecare iterație de parametri. Pentru matrici extrem de mari, aceasta are un cost computațional ridicat.
2.2 Fluxul de lucru cuantic și grupurile de Pauli comutativi
Acum imaginează-ți că delegi această parte a calculului unui calculator cuantic. În loc să calculezi această valoare de așteptare, o estimezi pregătind starea pe calculatorul cuantic folosind ansatz-ul tău variațional, și apoi efectuând măsurători.
Asta poate suna mai ușor decât este. în general nu este ușor de măsurat. De exemplu, ar putea fi alcătuit din mulți operatori Pauli X, Y și Z care nu comutează. Dar poate fi scris ca o combinație liniară de termeni, , fiecare dintre care este ușor de măsurat (de exemplu, operatori Pauli sau grupuri de operatori Pauli care comutează qubit-cu-qubit). Valoarea de așteptare a lui pe o anumită stare este suma ponderată a valorilor de așteptare ale termenilor constituenți . Această expresie este valabilă pentru orice stare , dar o vom folosi specific cu stările noastre variaționare .
unde este un șir Pauli precum IZZX…XIYX, sau mai multe astfel de șiruri care comutează între ele. Deci o descriere a valorii de așteptare care se potrivește mai bine cu realitățile măsurătorii pe calculatoarele cuantice este
Și în contextul funcției noastre de undă variaționare:
Fiecare dintre termenii poate fi măsurat de ori, obținând mostre de măsurătoare cu , și returnează o valoare de așteptare și o deviație standard . Putem suma acești termeni și propaga erorile prin sumă pentru a obține o valoare de așteptare globală și o deviație standard .
Aceasta nu necesită multiplicare la scară largă, nici vreun proces care să scaleze neapărat ca . În schimb, necesită multiple măsurători pe calculatorul cuantic. Dacă nu ai nevoie de prea multe, această abordare ar putea fi eficientă. Și acesta este aspectul cuantic al VQE.
Dar să vorbim despre motivele pentru care aceasta ar putea să nu fie eficientă. Un motiv pentru multe măsurători este reducerea incertitudinii statistice în estimările tale, pentru calcule de foarte mare precizie. Un alt motiv este numărul de șiruri Pauli necesare pentru a acoperi întreaga ta matrice. Deoarece matricile Pauli (plus identitatea: X, Y, Z și I) acoperă spațiul tuturor operatorilor de o dimensiune dată, suntem garantați că putem scrie matricea noastră de interes ca o sumă ponderată de operatori Pauli, așa cum am făcut înainte.
unde este un șir Pauli care acționează pe toți qubiții care descriu sistemul tău, ca IZZX…XIYX, sau mai multe astfel de șiruri care comutează între ele. Amintește-ți că Qiskit folosește notația little endian, în care al operator Pauli de la dreapta acționează pe al qubit. Deci putem măsura operatorul nostru măsurând o serie de operatori Pauli.
Dar nu putem măsura toți acești operatori Pauli simultan. Operatorii Pauli (excluzând I) nu comutează între ei dacă sunt asociați cu același qubit. De exemplu, putem măsura IZIZ și ZZXZ simultan, deoarece putem măsura I și Z simultan pentru al treilea qubit, și putem cunoaște I și X simultan pentru primul qubit. Dar nu putem măsura ZZZZ și ZZZX simultan, deoarece Z și X nu comutează, și ambele acționează pe al 0-lea qubit. Cititorii experimentați ar putea aminti că două grupuri de operatori Pauli pot comuta ca set, chiar dacă măsurătorile qubiților individuali nu comutează. Estimator presupune măsurători Pauli tensoriale (prin rotații de bază), corespunzând grupării operatorilor care comutează qubit cu qubit. Astfel, pentru a estima simultan două șiruri (A și B) de operatori Pauli folosind Estimator, operatorii Pauli ai fiecărui qubit din A și B trebuie să comute. Aceasta înseamnă că nu putem măsura nici ZZZZ și ZZXX simultan.

Deci descompunem matricea noastră într-o sumă de Pauli care acționează pe diferiți qubiți. Unele elemente ale acelei sume pot fi măsurate deodată; numim asta un grup de Pauli comutativi. În funcție de câți termeni necomutatori există, este posibil să avem nevoie de multe astfel de grupuri. Notăm numărul de astfel de grupuri de șiruri Pauli comutativi cu . Dacă este mic, ar putea funcționa bine. Dacă are milioane de grupuri, nu va fi util.
Procesele necesare pentru estimarea valorii de așteptare sunt colectate în primitivul Qiskit Runtime numit Estimator. Pentru a afla mai multe despre Estimator, vezi referința API în Documentația IBM Quantum®. Se poate folosi Estimator direct, dar Estimator returnează mult mai mult decât valoarea proprie minimă a energiei. De exemplu, returnează și informații despre eroarea standard a ansamblului. Astfel, în contextul problemelor de minimizare, Estimator se găsește adesea în interiorul unei funcții de cost. Pentru a afla mai multe despre intrările și ieșirile Estimator, vezi acest ghid din Documentația IBM Quantum.
Înregistrezi valoarea de așteptare (sau funcția de cost) pentru setul de parametri folosiți în starea ta, și apoi actualizezi parametrii. În timp, poți folosi valorile de așteptare sau valorile funcției de cost pe care le-ai estimat pentru a aproxima un gradient al funcției tale de cost în subspațiul de stări eșantionate de ansatz-ul tău. Există atât optimizatori clasici bazați pe gradient, cât și fără gradient. Ambele suferă de potențiale probleme de antrenabilitate, cum ar fi mai mulți minimai locali, și regiuni mari ale spațiului parametrilor cu gradient aproape zero, numite platouri goale (barren plateaus).

2.3 Factorii care determină costul computațional
VQE nu va rezolva toate problemele tale de chimie cuantică cele mai dificile. Nu. Dar a fi mai bun la toate calculele nu este ideea. Am deplasat ceea ce determină costul computațional.

Am trecut de la un proces a cărui complexitate depinde doar de dimensiunea matricei la unul care depinde de precizia necesară și de numărul de operatori Pauli necomutatori care alcătuiesc matricea. Ultima parte nu are analog în calculul clasic.
Pe baza acestor dependențe, pentru matrici rare, sau matrici care implică puține șiruri Pauli necomutatoare, acest proces poate fi util. Acesta este cazul sistemelor de spini în interacțiune, de exemplu. Pentru matrici dense, poate fi mai puțin util. Știm de exemplu că sistemele chimice au adesea Hamiltonieni care implică sute, mii, chiar milioane de șiruri Pauli. S-a realizat muncă interesantă pentru a reduce acest număr de termeni. Dar sistemele chimice s-ar putea potrivi mai bine cu unii dintre ceilalți algoritmi pe care îi vom discuta în acest curs.
Verifică-ți înțelegerea
Consideră un Hamiltonian pe patru qubiți care conține termenii:
IIXX, IIXZ, IIZZ, IZXZ, IXXZ, ZZXZ, XZXZ, ZIXZ, ZZZZ, XXXX
Vrei să sortezi acești termeni în grupuri astfel încât toți termenii dintr-un grup să poată fi măsurați simultan. Care este numărul minim de astfel de grupuri pe care le poți face astfel încât toți termenii să fie acoperiți?
Răspuns
Se poate face în 4 grupuri. Rețineți că astfel de soluții nu sunt de obicei unice.
IIXX, XXXX, IIZZ, ZZZZ
IIXZ, IZXZ, ZIXZ, ZZXZ
IXXZ
XZXZ
Ce crezi că face de obicei chimia cuantică cu VQE dificilă: numărul de termeni din Hamiltonian sau găsirea unui ansatz bun?
Răspuns
Se dovedește că există ansätze foarte optimizate pentru contexte chimice. Numărul de termeni din Hamiltonian, și deci numărul de măsurători necesare, cauzează de obicei mai multe probleme.
3. Exemplu de Hamiltonian
Să punem acest algoritm în practică folosind o matrice Hamiltonian mică, astfel încât să putem vedea ce se întâmplă la fiecare pas. Vom utiliza cadrul de lucru Qiskit patterns:
-Pasul 1: Mapează problema pe circuite cuantice și operatori -Pasul 2: Optimizează pentru hardware-ul țintă -Pasul 3: Execută pe hardware-ul țintă -Pasul 4: Post-procesează rezultatele
3.1 Pasul 1: Maparea problemei pe circuite cuantice și operatori
Vom folosi cel definit mai sus din contextul chimiei. Începem cu câteva importuri generale.
# General imports
import numpy as np
# SciPy minimizer routine
from scipy.optimize import minimize
# Plotting functions
import matplotlib.pyplot as plt
Din nou, presupunem că Hamiltonianul de interes este cunoscut. Vom folosi un Hamiltonian extrem de mic aici, deoarece alte metode discutate în acest curs vor fi mai eficiente la rezolvarea problemelor mai mari.
from qiskit.quantum_info import SparsePauliOp
import numpy as np
hamiltonian = SparsePauliOp.from_list(
[("YZ", 0.3980), ("ZI", -0.3980), ("ZZ", -0.0113), ("XX", 0.1810)]
)
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues))
The ground state energy is -0.702930394459531
Există multe alegeri de ansatz prefabricate în Qiskit. Vom folosi efficient_su2.
# Pre-defined ansatz circuit and operator class for Hamiltonian
from qiskit.circuit.library import efficient_su2
# Note that it is more common to place initial 'h' gates outside the ansatz.
# Here we specifically wanted this layer structure.
ansatz = efficient_su2(
hamiltonian.num_qubits, su2_gates=["h", "rz", "y"], entanglement="circular", reps=1
)
num_params = ansatz.num_parameters
print("This circuit has ", num_params, "parameters")
ansatz.decompose().draw("mpl", style="iqp")
This circuit has 4 parameters
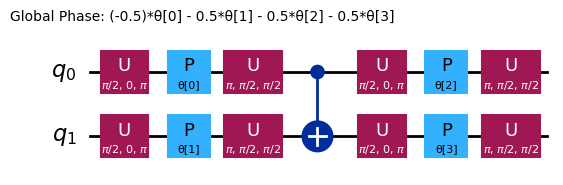
Diferitele ansätze vor avea structuri de împletire diferite și Gate-uri de rotație diferite. Cel arătat aici folosește Gate-uri CNOT pentru împletire, și atât Gate-uri Y cât și Gate-uri RZ parametrizate pentru rotații. Observă dimensiunea acestui spațiu de parametri; înseamnă că trebuie să minimizăm funcția de cost pe 4 variabile (parametrii pentru Gate-urile RZ). Aceasta poate fi scalată, dar nu la infinit. Rulând o problemă similară pe 4 qubiți, folosind cele 3 repetări implicite pentru efficient_su2 produce 16 parametri variaționali.
3.2 Pasul 2: Optimizarea pentru hardware-ul țintă
Ansatz-ul a fost scris folosind Gate-uri familiare, dar Circuit-ul nostru trebuie transpilat pentru a folosi Gate-urile de bază care pot fi implementate pe fiecare calculator cuantic. Selectăm Backend-ul cel mai puțin ocupat.
# runtime imports
from qiskit_ibm_runtime import QiskitRuntimeService, Session
from qiskit_ibm_runtime import EstimatorV2 as Estimator
# To run on hardware, select the backend with the fewest number of jobs in the queue
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
print(backend)
<IBMBackend('ibm_torino')>
Acum putem transpila Circuit-ul nostru pentru acest hardware și vizualiza ansatz-ul nostru transpilat.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
ansatz_isa = pm.run(ansatz)
ansatz_isa.draw(output="mpl", idle_wires=False, style="iqp")

Observă că Gate-urile folosite s-au schimbat, iar qubiții din Circuit-ul nostru abstract au fost mapați pe qubiți numerotați diferit pe calculatorul cuantic. Trebuie să mapăm Hamiltonianul nostru identic pentru ca rezultatele să fie semnificative.
hamiltonian_isa = hamiltonian.apply_layout(layout=ansatz_isa.layout)
3.3 Pasul 3: Execuție pe hardware-ul țintă
3.3.1 Raportarea valorilor
Definim aici o funcție de cost care primește ca argumente structurile pe care le-am construit în pașii anteriori: parametrii, ansatz-ul și Hamiltonianul. Folosește și Estimator-ul pe care nu l-am definit încă. Includem cod pentru a urmări istoricul funcției noastre de cost, astfel încât să putem verifica comportamentul de convergență.
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from Estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (EstimatorV2): Estimator primitive instance
cost_history_dict: Dictionary for storing intermediate results
Returns:
float: Energy estimate
"""
pub = (ansatz, [hamiltonian], [params])
result = estimator.run(pubs=[pub]).result()
energy = result[0].data.evs[0]
cost_history_dict["iters"] += 1
cost_history_dict["prev_vector"] = params
cost_history_dict["cost_history"].append(energy)
print(f"Iters. done: {cost_history_dict['iters']} [Current cost: {energy}]")
return energy
cost_history_dict = {
"prev_vector": None,
"iters": 0,
"cost_history": [],
}
Este foarte avantajos dacă poți alege valorile inițiale ale parametrilor pe baza cunoașterii problemei la îndemână și a caracteristicilor stării țintă. Nu vom face nicio ipoteză despre o astfel de cunoaștere și vom folosi valori inițiale aleatoare.
x0 = 2 * np.pi * np.random.random(num_params)
# This required 13 min, 20 s QPU time on an Eagle processor, 28 min total time.
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
estimator.options.default_shots = 10000
res = minimize(
cost_func,
x0,
args=(ansatz_isa, hamiltonian_isa, estimator),
method="cobyla",
options={"maxiter": 50},
)
Iters. done: 1 [Current cost: 0.010575798722044727]
Iters. done: 2 [Current cost: 0.004040015974440895]
Iters. done: 3 [Current cost: 0.0020213258785942503]
Iters. done: 4 [Current cost: 0.18723082446726014]
Iters. done: 5 [Current cost: -0.2746792152068885]
Iters. done: 6 [Current cost: -0.3094547651648519]
Iters. done: 7 [Current cost: -0.05281985428356641]
Iters. done: 8 [Current cost: 0.00808560303514377]
Iters. done: 9 [Current cost: -0.0014821685303514388]
Iters. done: 10 [Current cost: -0.004759824281150161]
Iters. done: 11 [Current cost: 0.09942328705995292]
Iters. done: 12 [Current cost: 0.01092366214057508]
Iters. done: 13 [Current cost: 0.05017497496069776]
Iters. done: 14 [Current cost: 0.13028868414310696]
Iters. done: 15 [Current cost: 0.013747803514376994]
Iters. done: 16 [Current cost: 0.2583072432944498]
Iters. done: 17 [Current cost: -0.14422125655131562]
Iters. done: 18 [Current cost: -0.0004950150347678081]
Iters. done: 19 [Current cost: 0.00681082268370607]
Iters. done: 20 [Current cost: -0.0023377795527156544]
Iters. done: 21 [Current cost: 0.6027665591169237]
Iters. done: 22 [Current cost: 0.00596641373801917]
Iters. done: 23 [Current cost: -0.008318769968051117]
Iters. done: 24 [Current cost: -0.00026683306709265246]
Iters. done: 25 [Current cost: -0.007648222843450479]
Iters. done: 26 [Current cost: 0.004121086261980831]
Iters. done: 27 [Current cost: -0.004075019968051117]
Iters. done: 28 [Current cost: -0.004419369009584665]
Iters. done: 29 [Current cost: 0.213185460054037]
Iters. done: 30 [Current cost: -0.06505919572162797]
Iters. done: 31 [Current cost: -0.5334241316590271]
Iters. done: 32 [Current cost: 0.00218370607028754]
Iters. done: 33 [Current cost: 0.09579352143666908]
Iters. done: 34 [Current cost: -0.009274800319488819]
Iters. done: 35 [Current cost: -0.44395141360688106]
Iters. done: 36 [Current cost: 0.011747104632587858]
Iters. done: 37 [Current cost: -0.003344149361022364]
Iters. done: 38 [Current cost: 0.19138183916486304]
Iters. done: 39 [Current cost: 0.013513931813145209]
Putem analiza ieșirile brute.
res
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.5334241316590271
x: [ 1.024e+00 6.459e+00 3.625e+00 4.007e+00]
nfev: 39
maxcv: 0.0
3.4 Pasul 4: Post-procesarea rezultatelor
Dacă procedura se termină corect, atunci valorile din dicționarul nostru ar trebui să fie egale cu vectorul soluție și numărul total de evaluări ale funcției, respectiv. Aceasta este ușor de verificat:
cost_history_dict
{'prev_vector': array([1.02397956, 6.45886604, 3.62479262, 4.00744128]),
'iters': 39,
'cost_history': [np.float64(0.010575798722044727),
np.float64(0.004040015974440895),
np.float64(0.0020213258785942503),
np.float64(0.18723082446726014),
np.float64(-0.2746792152068885),
np.float64(-0.3094547651648519),
np.float64(-0.05281985428356641),
np.float64(0.00808560303514377),
np.float64(-0.0014821685303514388),
np.float64(-0.004759824281150161),
np.float64(0.09942328705995292),
np.float64(0.01092366214057508),
np.float64(0.05017497496069776),
np.float64(0.13028868414310696),
np.float64(0.013747803514376994),
np.float64(0.2583072432944498),
np.float64(-0.14422125655131562),
np.float64(-0.0004950150347678081),
np.float64(0.00681082268370607),
np.float64(-0.0023377795527156544),
np.float64(0.6027665591169237),
np.float64(0.00596641373801917),
np.float64(-0.008318769968051117),
np.float64(-0.00026683306709265246),
np.float64(-0.007648222843450479),
np.float64(0.004121086261980831),
np.float64(-0.004075019968051117),
np.float64(-0.004419369009584665),
np.float64(0.213185460054037),
np.float64(-0.06505919572162797),
np.float64(-0.5334241316590271),
np.float64(0.00218370607028754),
np.float64(0.09579352143666908),
np.float64(-0.009274800319488819),
np.float64(-0.44395141360688106),
np.float64(0.011747104632587858),
np.float64(-0.003344149361022364),
np.float64(0.19138183916486304),
np.float64(0.013513931813145209)]}
fig, ax = plt.subplots()
x = np.linspace(0, 10, 50)
# Define the constant function
constant = -0.7029
y_constant = np.full_like(x, constant)
ax.plot(
range(cost_history_dict["iters"]), cost_history_dict["cost_history"], label="VQE"
)
ax.set_xlabel("Iterations")
ax.set_ylabel("Cost")
ax.plot(y_constant, label="Target")
plt.legend()
plt.draw()

IBM Quantum are alte oferte de perfecționare legate de VQE. Dacă ești gata să pui VQE în practică, vezi tutorialul nostru: Ground-state energy estimation of the Heisenberg chain with VQE. Dacă vrei mai multe informații despre crearea Hamiltonienilor moleculari, vezi această lecție din cursul nostru despre Quantum chemistry with VQE. Dacă ești interesat de o înțelegere mai profundă a modului în care funcționează algoritmii variaționali precum VQE, recomandăm cursul Variational Algorithm Design.
Verifică-ți înțelegerea
În această secțiune, am calculat o energie a stării de bază dintr-un Hamiltonian. Dacă am vrea să aplicăm aceasta pentru, să zicem, determinarea geometriei unei molecule, cum am extinde asta?
Răspuns
Ar trebui să introducem variabile pentru spațierea inter-atomică și unghiurile dintre legături. Ar trebui să le variăm pe acestea. Pentru fiecare variație a acestora, am produce un nou Hamiltonian (deoarece operatorii care descriu energia depind cu certitudine de geometrie). Pentru fiecare astfel de Hamiltonian produs și mapat pe qubiți, ar trebui să efectuăm o optimizare ca cea de mai sus. Dintre toate acele probleme de optimizare convergate, geometria care a produs cea mai mică energie ar fi cea adoptată de natură. Aceasta este mult mai implicat decât ce s-a arătat mai sus. Un astfel de calcul este realizat pentru cea mai simplă moleculă, , aici.
4. Relația VQE cu alte metode
În această secțiune vom examina avantajele și dezavantajele abordării originale VQE și vom sublinia relațiile sale cu alți algoritmi mai recenți.
4.1 Punctele forte și slabe ale VQE
Câteva puncte forte au fost deja menționate. Acestea includ:
- Potrivire pentru hardware-ul modern: Unii algoritmi cuantici necesită rate de eroare mult mai mici, apropiindu-se de toleranța la erori la scară largă. VQE nu; poate fi implementat pe calculatoarele cuantice actuale.
- Circuite puțin adânci: VQE folosește adesea circuite cuantice relativ puțin adânci. Aceasta face VQE mai puțin susceptibil la erorile acumulate ale Gate-urilor și îl face potrivit pentru multe tehnici de atenuare a erorilor. Bineînțeles, circuitele nu sunt întotdeauna puțin adânci; aceasta depinde de ansatz-ul folosit.
- Versatilitate: VQE poate fi aplicat (în principiu) oricărei probleme care poate fi formulată ca o problemă de valori proprii/vectori proprii. Există multe avertismente care fac VQE impractical sau dezavantajos pentru unele probleme. Unele dintre acestea sunt rezumate mai jos.
Câteva slăbiciuni ale VQE și probleme pentru care este impractical au fost, de asemenea, descrise mai sus. Acestea includ:
- Natura euristică: VQE nu garantează convergența la energia corectă a stării de bază, deoarece performanța sa depinde de alegerea ansatz-ului și a metodelor de optimizare[1-2]. Dacă se alege un ansatz slab care îi lipsește împletirea necesară pentru starea de bază dorită, niciun optimizator clasic nu poate atinge acea stare de bază.
- Potențial numeroși parametri: Un ansatz foarte expresiv poate avea atât de mulți parametri încât iterațiile de minimizare sunt foarte consumatoare de timp.
- Overhead ridicat de măsurători: În VQE, Estimator este folosit pentru a estima valoarea de așteptare a fiecărui termen din Hamiltonian. Majoritatea Hamiltonienilor de interes vor avea termeni care nu pot fi estimați simultan. Aceasta poate face VQE intensiv în resurse pentru sisteme mari cu Hamiltonieni complicați[1].
- Efectele zgomotului: Când optimizatorul clasic caută un minim, calculele zgomotoase îl pot deruta și îl pot îndepărta de minimul adevărat sau îi pot întârzia convergența. O posibilă soluție pentru aceasta este utilizarea tehnicilor de ultimă generație de atenuare și suprimare a erorilor[2-3] de la IBM.
- Platouri goale (barren plateaus): Aceste regiuni de gradienți dispăruți[2-3] există chiar și în absența zgomotului, dar zgomotul le face mai problematice, deoarece schimbarea valorilor de așteptare din cauza zgomotului ar putea fi mai mare decât schimbarea din actualizarea parametrilor în aceste regiuni goale.
4.2 Relația cu alte abordări
Adapt-VQE
Algoritmul ADAPT-VQE (Adaptive Derivative-Assembled Pseudo-Trotter Variational Quantum Eigensolver) este o îmbunătățire a algoritmului VQE original, concepută pentru a îmbunătăți eficiența, precizia și scalabilitatea pentru simulările cuantice, în special în chimia cuantică.
Algoritmul VQE original descris pe tot parcursul acestei lecții folosește un ansatz predefinit, fix pentru a aproxima starea de bază a sistemului. În cazul nostru, am folosit efficient_su2, cu o singură repetare, folosind Gate-uri de rotație Y și RZ. Deși parametrii din Gate-urile RZ s-au schimbat, structura acestui ansatz și Gate-urile folosite nu s-au schimbat.
ADAPT-VQE abordează limitările VQE prin construcția adaptivă a ansatz-ului. În loc să înceapă cu un ansatz fix, ADAPT-VQE construiește dinamic ansatz-ul iterativ. La fiecare pas, selectează operatorul dintr-un pool predefinit (cum ar fi operatorii de excitație fermionici) care are cel mai mare gradient față de energie. Aceasta garantează că sunt adăugați doar operatorii cu cel mai mare impact, conducând la un ansatz compact și eficient[4-6]. Această abordare poate avea mai multe efecte benefice:
- Adâncime redusă a Circuit-ului: Prin creșterea ansatz-ului incremental și concentrarea doar pe operatorii necesari, ADAPT-VQE minimizează operațiile Gate față de abordările VQE tradiționale[5,7].
- Precizie îmbunătățită: Natura adaptivă permite ADAPT-VQE să recupereze mai multă energie de corelație la fiecare pas, făcându-l deosebit de eficient pentru sistemele puternic corelate unde VQE tradițional se luptă[8,9].
- Scalabilitate și robustețe la zgomot: Ansatz-ul compact reduce acumularea erorilor de poartă, reduce overhead-ul computațional și limitează numărul de parametri variaționali care trebuie minimizați.
ADAPT-VQE nu este încă perfect. În unele cazuri poate deveni blocat sau încetinit de minimele locale, și poate suferi de supra-parametrizare. Poate fi, de asemenea, destul de intensiv în resurse, deoarece necesită calculul gradienților și optimizarea parametrilor cu multe structuri de poartă.
Estimarea fazei cuantice (QPE)
QPE este similar ca scop cu VQE, dar foarte diferit în implementare. QPE necesită calculatoare cuantice tolerante la erori din cauza circuitelor sale cuantice în general adânci și a nivelului ridicat de coerență pe care îl necesită. Odată ce QPE poate fi implementat, ar fi mai precis decât VQE. Un mod de a descrie diferența este prin precizie ca funcție de adâncimea Circuit-ului. QPE atinge precizia cu adâncimi ale Circuit-ului scalând ca [10]. VQE necesită mostre pentru a atinge aceeași precizie[10,11].
Krylov, SQD, QSCI și alții în acest curs
VQE a ajutat la stabilirea algoritmilor cuantici care depind în continuare de calculatoarele clasice, nu doar pentru operarea calculatorului cuantic, ci și pentru părți substanțiale ale algoritmului. Mai mulți astfel de algoritmi sunt obiectul restului acestui curs. Aici oferim o explicație sumară a câtorva, pur și simplu pentru a le compara și contrasta cu VQE. Vor fi explicați în mult mai mare detaliu în lecțiile ulterioare.
Diagonalizarea cuantică Krylov (KQD)
Metodele de subspațiu Krylov sunt modalități de a proiecta o matrice pe un subspațiu pentru a-i reduce dimensiunea și a o face mai gestionabilă, păstrând în același timp cele mai importante caracteristici. Un truc în această metodă este generarea unui subspațiu care păstrează aceste caracteristici; se dovedește că generarea acestui subspațiu este strâns legată de o metodă bine stabilită pe calculatoarele cuantice numită Trotterizare.
Există câteva variante ale metodelor cuantice Krylov, dar în general abordarea este:
- Folosește calculatorul cuantic pentru a genera un subspațiu (subspațiul Krylov) prin Trotterizare
- Proiectează matricea de interes pe acel subspațiu Krylov
- Diagonalizează noul Hamiltonian proiectat folosind un calculator clasic
Diagonalizarea cuantică bazată pe eșantionare (SQD)
Diagonalizarea cuantică bazată pe eșantionare (SQD) este legată de metoda Krylov prin aceea că încearcă, de asemenea, să reducă dimensiunea unei matrici de diagonalizat, păstrând în același timp caracteristicile cheie. SQD face asta în felul următor:
- Începe cu o presupunere inițială pentru starea ta de bază și pregătește sistemul în acea stare de bază.
- Folosește Sampler pentru a eșantiona șirurile de biți care alcătuiesc această stare.
- Folosește colecția de stări ale bazei computaționale din Sampler ca subspațiu pe care proiectezi matricea ta de interes.
- Diagonalizează matricea mai mică, proiectată folosind un calculator clasic.
Aceasta este legată de VQE prin faptul că utilizează atât calculul clasic cât și cel cuantic pentru componente substanțiale ale algoritmului. Ambele împărtășesc, de asemenea, cerința de a pregăti o presupunere inițială bună sau un ansatz. Dar distribuția muncii între calculatoarele clasice și cuantice în SQD este mai mult ca cea a metodei Krylov.
De fapt, metoda Krylov și SQD au fost recent combinate în metoda de diagonalizare cuantică Krylov bazată pe eșantionare (SKQD) [12].
Interacțiunea de configurație a subspațiului cuantic
Quantum Selected Configuration Interaction (QSCI)[13] este un algoritm care produce o stare de bază aproximată a unui Hamiltonian prin eșantionarea unei funcții de undă de probă pentru a identifica stările semnificative ale bazei computaționale și a genera un subspațiu pentru o diagonalizare clasică. Atât SQD cât și QSCI folosesc un calculator cuantic pentru a construi un subspațiu redus. Punctul forte suplimentar al QSCI constă în pregătirea stării, mai ales în contextul problemelor de chimie. Acesta utilizează diverse strategii, cum ar fi folosirea stărilor evoluate în timp [14] și un set de ansätze inspirate din chimie. Concentrându-se pe pregătirea eficientă a stării, QSCI reduce costurile computaționale cuantice pentru Hamiltonieni chimici, menținând în același timp o fidelitate ridicată și valorificând robustețea la zgomot din tehnicile de eșantionare a stărilor cuantice [15]. QSCI oferă, de asemenea, o tehnică de construcție adaptivă care furnizează mai multe ansätze pentru un rezultat mai bun.
Fluxul de lucru implicit al QSCI pentru problema de chimie este după cum urmează:
- Construiește Hamiltonianul molecular folosind software-ul la alegere (cum ar fi SciPy).
- Pregătește un algoritm QSCI selectând o stare inițială adecvată și un ansatz inspirat din chimie cu un set pre-selectat de parametri.
- Eșantionează stările de bază semnificative și diagonalizează Hamiltonianul folosind un calculator clasic pentru a obține energia stării de bază.
- Adesea se folosesc recuperarea configurației [16] și postselectarea simetriei [15] ca tehnică de post-procesare.
- Opțional, fluxul de lucru al QSCI adaptiv are o buclă de optimizare suplimentară de la pasul 2 la pasul 3, folosind mai multe ansätze cu stări inițiale aleatoare.
Verifică-ți înțelegerea
Ce are VQE în comun cu toate celelalte metode enumerate mai sus (cu excepția QPE care nu este descrisă în detaliu mare)
Răspuns
Toate implică o stare de probă sau o funcție de undă de un anumit fel. Toate funcționează cel mai bine atunci când presupunerea inițială pentru această stare de probă este excelentă.
Un alt răspuns corect este că toate sunt cel mai ușor de implementat atunci când Hamiltonianul este ușor de măsurat (poate fi sortat în relativ puține grupuri de operatori Pauli comutativi).
Ce are VQE în comun cu niciuna dintre celelalte metode enumerate mai sus?
Răspuns
Optimizatorii clasici. Niciunul dintre ceilalți nu folosesc algoritmi de optimizare clasici pentru a selecta parametri variaționali.
Referințe
[2] https://en.wikipedia.org/wiki/Variational_quantum_eigensolver
[3] https://journals.aps.org/prapplied/abstract/10.1103/PhysRevApplied.19.024047
[4] https://arxiv.org/abs/2111.05176
[6] https://inquanto.quantinuum.com/tutorials/InQ_tut_fe4n2_2.html
[7] https://www.nature.com/articles/s41467-019-10988-2
[8] https://arxiv.org/abs/2210.15438
[9] https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.6.013254
[10] https://arxiv.org/html/2403.09624v1
[11] https://www.nature.com/articles/s42005-023-01312-y
[13] https://arxiv.org/abs/1802.00171
[14] https://arxiv.org/abs/2103.08505
[15] https://arxiv.org/html/2501.09702v1
[16] https://quri-sdk.qunasys.com/docs/examples/quri-algo-vm/qsci/