Diagonalizarea Krylov cuantică
În această lecție despre diagonalizarea Krylov cuantică (KQD) vom răspunde la următoarele întrebări:
- Ce este metoda Krylov, în general?
- De ce funcționează metoda Krylov și în ce condiții?
- Cum intervine calculul cuantic?
Partea cuantică a calculelor se bazează în mare parte pe lucrarea din Ref [1].
Videoclipul de mai jos oferă o prezentare generală a metodelor Krylov în calculul clasic, motivează utilizarea lor și explică cum poate interveni calculul cuantic în acest flux de lucru. Textul următor oferă mai multe detalii și implementează o metodă Krylov atât clasic, cât și folosind un calculator cuantic.
1. Introducere în metodele Krylov
O metodă a subspațiului Krylov poate face referire la oricare dintre mai multe metode construite în jurul a ceea ce se numește subspațiul Krylov. O prezentare completă a acestora depășește scopul acestei lecții, însă Ref [2-4] pot oferi un fundal substanțial mai detaliat. Aici ne vom concentra pe ce este un subspațiu Krylov, cum și de ce este util în rezolvarea problemelor de valori proprii, și, în final, cum poate fi implementat pe un calculator cuantic. Definiție: Dată o matrice simetrică și pozitiv semi-definită , spațiul Krylov de ordinul este spațiul generat de vectorii obținuți prin înmulțirea puterilor crescătoare ale matricei , până la , cu un vector de referință .
Deși vectorii de mai sus generează ceea ce numim un subspațiu Krylov, nu există niciun motiv să presupunem că vor fi ortogonali. Adesea se folosește un proces iterativ de ortonormare similar cu ortonormarea Gram-Schmidt. Aici procesul este puțin diferit, deoarece fiecare vector nou este făcut ortogonal față de ceilalți pe măsură ce este generat. În acest context, procesul se numește iterația Arnoldi. Pornind de la vectorul inițial , se generează următorul vector , după care se asigură că al doilea vector este ortogonal față de primul prin scăderea proiecției sale pe . Adică
Acum este ușor de văzut că deoarece
Facem același lucru pentru următorul vector, asigurându-ne că este ortogonal față de ambii vectori anteriori:
Dacă repetăm acest proces pentru toți cei vectori, avem o bază ortonormată completă pentru un spațiu Krylov. Observă că procesul de ortonormare va produce zero odată ce , deoarece vectori ortogonali acoperă în mod necesar spațiul complet. Procesul va produce de asemenea zero dacă vreun vector este un vector propriu al lui , deoarece toți vectorii următori vor fi multipli ai acelui vector.
1.1 Un exemplu simplu: Krylov de mână
Să parcurgem pas cu pas generarea unui subspațiu Krylov pe o matrice extrem de mică, astfel încât să putem vedea procesul. Începem cu o matrice inițială care ne interesează:
Pentru acest exemplu mic, putem determina ușor vectorii proprii și valorile proprii chiar și manual. Prezentăm aici soluția numerică.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy sympy
# One might use linalg.eigh here, but later matrices may not be Hermitian. So we use
# linalg.eig in this lesson.
import numpy as np
A = np.array([[4, -1, 0], [-1, 4, -1], [0, -1, 4]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
The eigenvalues are [2.58578644 4. 5.41421356]
The eigenvectors are [[ 5.00000000e-01 -7.07106781e-01 5.00000000e-01]
[ 7.07106781e-01 1.37464400e-16 -7.07106781e-01]
[ 5.00000000e-01 7.07106781e-01 5.00000000e-01]]
Le notăm aici pentru comparație ulterioară:
Am dori să studiem cum funcționează (sau eșuează) acest proces pe măsură ce creștem dimensiunea subspațiului nostru Krylov, . În acest scop, vom aplica procesul următor:
- Generează un subspațiu al spațiului vectorial complet pornind de la un vector ales aleatoriu (numește-l dacă este deja normalizat, ca mai sus).
- Proiectează matricea completă pe acel subspațiu și găsește valorile proprii ale acelei matrici proiectate .
- Mărește dimensiunea subspațiului generând mai mulți vectori, asigurând că aceștia sunt ortonormați, folosind un proces similar cu ortonormarea Gram-Schmidt.
- Proiectează pe subspațiul mai mare și găsește valorile proprii ale matricii rezultante, .
- Repetă acest lucru până când valorile proprii converg (sau, în acest caz de jucărie, până când ai generat vectori ce acoperă spațiul vectorial complet al matricei originale ).
O implementare normală a metodei Krylov nu ar trebui să rezolve problema valorilor proprii pentru matricea proiectată pe fiecare subspațiu Krylov pe măsură ce este construit. Ai putea construi subspațiul de dimensiunea dorită, proiecta matricea pe acel subspațiu și diagonaliza matricea proiectată. Proiectarea și diagonalizarea la fiecare dimensiune a subspațiului se face doar pentru verificarea convergenței.
Dimensiunea :
Alegem un vector aleatoriu, să zicem
Dacă nu este deja normalizat, normalizează-l.
Acum proiectăm matricea noastră pe subspațiul acestui singur vector:
Aceasta este proiecția matricei pe subspațiul nostru Krylov atunci când acesta conține doar un singur vector, . Valoarea proprie a acestei matrici este trivial 4. Putem considera aceasta ca estimarea noastră de ordinul zero a valorilor proprii (în acest caz doar una) ale lui . Deși este o estimare slabă, are ordinul de mărime corect.
Dimensiunea :
Acum generăm următorul vector din subspațiul nostru prin aplicarea lui pe vectorul anterior:
Acum scădem proiecția acestui vector pe vectorul nostru anterior pentru a asigura ortogonalitatea.
Dacă nu este deja normalizat, normalizează-l. În acest caz, vectorul era deja normalizat, deci
Acum proiectăm matricea A pe subspațiul acestor doi vectori:
Rămânem cu problema determinării valorilor proprii ale acestei matrici. Dar această matrice este puțin mai mică decât matricea completă. În problemele ce implică matrici foarte mari, lucrul cu acest subspațiu mai mic poate fi extrem de avantajos.
Deși aceasta nu este încă o estimare bună, este mai bună decât estimarea de ordinul zero. Vom continua cu încă o iterație, pentru a ne asigura că procesul este clar. Totuși, aceasta subminează scopul metodei, deoarece vom ajunge să diagonalizăm o matrice 3x3 în iterația următoare, ceea ce înseamnă că nu am economisit timp sau putere de calcul.
Dimensiunea :
Acum generăm următorul vector din subspațiul nostru prin aplicarea lui A pe vectorul anterior:
Acum scădem proiecția acestui vector pe ambii vectori anteriori pentru a asigura ortogonalitatea.
Dacă nu este deja normalizat, normalizează-l. În acest caz, vectorul era deja normalizat, deci
Acum proiectăm matricea noastră pe subspațiul acestor vectori:
Acum determinăm valorile proprii:
Aceste valori proprii sunt exact valorile proprii ale matricei originale . Acest lucru trebuie să fie valabil, deoarece am extins subspațiul nostru Krylov pentru a acoperi întregul spațiu vectorial al matricei originale .
În acest exemplu, metoda Krylov poate să nu pară deosebit de mai ușoară decât diagonalizarea directă. Într-adevăr, după cum vom vedea în secțiunile ulterioare, metoda Krylov este avantajoasă doar peste o anumită dimensiune a matricei; aceasta este menită să ne ajute să rezolvăm probleme de valori proprii/vectori proprii pentru matrici extrem de mari.
Acesta este singurul exemplu pe care îl vom arăta rezolvat „manual", dar secțiunea 2 de mai jos prezintă exemple computaționale.
Clarificarea termenilor
O concepție greșită frecventă este că există un singur subspațiu Krylov pentru o problemă dată. Dar, desigur, deoarece există mulți vectori inițiali la care poate fi aplicată matricea noastră, există multe subspații Krylov posibile. Vom folosi expresia „subspațiul Krylov" pentru a ne referi la un subspațiu Krylov specific, deja definit pentru un exemplu specific. Pentru abordări generale de rezolvare a problemelor, vom ne referi la „un subspațiu Krylov". O clarificare finală: este valid să vorbim de un „spațiu Krylov". Adesea este numit „subspațiu Krylov" din cauza utilizării sale în contextul proiectării matricilor dintr-un spațiu inițial într-un subspațiu. Menținând acel context, îl vom numi în cea mai mare parte subspațiu aici.
Verifică-ți înțelegerea
Citește întrebările de mai jos, gândește-te la răspuns, apoi apasă pe triunghi pentru a dezvălui fiecare soluție.
Explică de ce nu este (a) util și (b) posibil să extinzi dimensiunea subspațiului Krylov peste dimensiunea a matricei de interes.
Răspuns:
(a) Deoarece ortonormăm vectorii pe măsură ce îi producem, un set de astfel de vectori va forma o bază completă, ceea ce înseamnă că o combinație liniară a lor poate fi folosită pentru a crea orice vector din spațiu. (b) Procesul de ortonormare constă în scăderea proiecției unui vector nou pe toți vectorii anteriori. Dacă toți vectorii anteriori acoperă spațiul vectorial complet, atunci scăderea proiecțiilor pe subspațiul complet va lăsa întotdeauna un vector nul.
Presupune că un coleg cercetător demonstrează metoda Krylov aplicată pe o matrice mică de jucărie pentru niște colegi. Acest coleg intenționează să folosească matricea și vectorul inițial:
și
Este ceva în neregulă cu asta? Cum l-ai sfătui pe colegul tău?
Răspuns:
Colegul tău a ales accidental un vector propriu ca vector inițial. Aplicarea matricei pe vectorul inițial va returna pur și simplu același vector, scalat cu valoarea proprie. Aceasta nu va genera un subspațiu de dimensiune crescătoare. Sfătuiește-ți colegul să aleagă un alt vector inițial, asigurându-se că nu este un vector propriu.
Aplică metoda Krylov pe matricea de mai jos, selectând un vector inițial adecvat nou. Scrie estimările valorii proprii minime la ordinul 0 și ordinul 1 al subspațiului tău Krylov.
Răspuns:
Există multe răspunsuri posibile în funcție de alegerea vectorului inițial. Vom alege:
Pentru a obține aplicăm o dată pe , apoi facem ortogonal față de
La ordinul 0, proiecția pe subspațiul nostru Krylov este
La ordinul 1, proiecția pe acest subspațiu Krylov este
Aceasta poate fi făcută manual, dar se face cel mai ușor folosind numpy:
import numpy as np
vstar = np.array([[1/np.sqrt(3),1/np.sqrt(3),1/np.sqrt(3)],[-1/np.sqrt(6),np.sqrt(2/3),-1/np.sqrt(6)]]
)
A = np.array([[1, 1, 0],
[1, 1, 1],
[0, 1, 1]])
v = np.array([[1/np.sqrt(3),-1/np.sqrt(6)],[1/np.sqrt(3),np.sqrt(2/3)],[1/np.sqrt(3),-1/np.sqrt(6)]])
proj = vstar@A@v
print(proj)
eigenvalues, eigenvectors = np.linalg.eig(proj)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
outputs:
[[ 2.33333333 0.47140452]
[ 0.47140452 -0.33333333]]
The eigenvalues are [ 2.41421356 -0.41421356]
The eigenvectors are [[ 0.98559856 -0.16910198]
[ 0.16910198 0.98559856]]
Estimarea valorii proprii minime este -0.414.
1.2 Tipuri de metode Krylov
„Metodele subspațiului Krylov" pot face referire la oricare dintre mai multe tehnici iterative folosite pentru a rezolva sisteme liniare mari și probleme de valori proprii. Ceea ce au toate în comun este că construiesc o soluție aproximativă dintr-un subspațiu Krylov
unde este estimarea inițială (vezi Ref [5]). Ele diferă în modul în care aleg cea mai bună aproximare din acest subspațiu, echilibrând factori precum rata de convergență, utilizarea memoriei și costul computațional total. Scopul acestei lecții este de a valorifica calculul cuantic în contextul metodelor subspațiului Krylov; o discuție exhaustivă a acestor metode depășește scopul ei. Definițiile scurte de mai jos sunt doar pentru context și includ câteva referințe pentru investigarea ulterioară a acestor metode.
Metoda gradientului conjugat (CG): Această metodă este folosită pentru rezolvarea sistemelor liniare simetrice, pozitiv definite[6]. Minimizează norma-A a erorii la fiecare iterație, făcând-o deosebit de eficientă pentru sistemele ce provin din EDP eliptice discretizate[7]. Vom folosi această abordare în secțiunea următoare pentru a motiva de ce un subspațiu Krylov ar fi un subspațiu eficient în care să căutăm soluții îmbunătățite la sisteme liniare.
Metoda reziduului minimal generalizat (GMRES): Aceasta este concepută pentru rezolvarea sistemelor liniare nesimetrice generale. Minimizează norma reziduului pe un spațiu Krylov la fiecare iterație, ceea ce o face robustă, dar potențial intensivă în memorie pentru sisteme mari[7].
Metoda reziduului minimal (MINRES): Această metodă este folosită pentru rezolvarea sistemelor liniare simetrice nedefinite pozitiv. Este similară cu GMRES, dar profită de simetria matricei pentru a reduce costul computațional[8].
Alte abordări notabile includ metoda ortonormalizării complete (FOM), care este strâns legată de metoda lui Arnoldi pentru probleme de valori proprii, metoda gradientului bi-conjugat (BiCG) și metoda reducerii dimensiunii induse (IDR).
1.3 De ce funcționează metoda subspațiului Krylov
Aici vom motiva că metoda subspațiului Krylov ar trebui să fie o modalitate eficientă de a aproxima valorile proprii ale matricei prin rafinare iterativă a aproximărilor vectorilor proprii, prin prisma coborârii în gradient. Vom argumenta că, dată o estimare inițială a stării fundamentale, spațiul corecțiilor succesive la acea estimare inițială care produce cea mai rapidă convergență este un subspațiu Krylov. Nu vom prezenta o demonstrație riguroasă a comportamentului de convergență.
Presupunem că matricea noastră de interes este simetrică și pozitiv definită. Aceasta face argumentul nostru cel mai relevant pentru metoda CG de mai sus. Nu facem nicio presupunere despre raritate (sparsitate) aici; nici nu susținem că trebuie să fie Hermitică (ceea ce este necesar dacă este un Hamiltonian).
De obicei dorim să rezolvăm o problemă de forma
S-ar putea imagina că unde este o constantă, ca într-o problemă de valori proprii. Dar formularea problemei rămâne mai generală pentru moment.
Începem cu un vector care este o soluție aproximativă. Deși există paralele între această estimare și din Secțiunea 1.1, nu le exploatăm aici. Estimarea noastră are eroare, pe care o numim
Definim de asemenea reziduul
Aici folosim majuscula pentru a distinge reziduul de dimensiunea a subspațiului nostru Krylov.

Acum vrem să facem un pas de corecție de forma
care sperăm că ne îmbunătățește aproximarea. Aici este un vector care rămâne de determinat. Fie eroarea după efectuarea corecției. Atunci

Suntem interesați de comportamentul erorii noastre atunci când este transformată de matricea noastră. Deci să calculăm norma-A a erorii. Adică
unde am folosit simetria lui și, de asemenea, că Aici este o constantă independentă de . Așa cum s-a menționat în Secțiunea 1.2, norma-A a erorii nu este singura cantitate pe care am putea alege să o minimizăm, dar este una bună. Vrem să vedem cum variază această cantitate cu alegerea vectorilor de corecție Deci definim funcția setând
este pur și simplu eroarea ca funcție a corecției măsurată în norma-A. Prin urmare, vrem să alegem astfel încât să fie cât mai mică posibil. În acest scop, calculăm gradientul lui . Folosind simetria lui avem
Gradientul indică direcția de ascensiune cea mai abruptă, ceea ce înseamnă că opusul său ne dă direcția în care funcția scade cel mai mult: direcția coborârii în gradient. La estimarea noastră inițială , unde , avem că Astfel, funcția scade cel mai mult în direcția reziduului Deci alegerea noastră inițială ar beneficia cel mai mult de adăugarea vectorului pentru un scalar .
La pasul următor, alegem din nou un vector și îi adăugăm valoarea la aproximarea curentă. Folosind același argument ca înainte alegem pentru un scalar . Continuăm în această manieră, astfel încât vectorul de la iterația a -a este
Echivalent, vrem să construim spațiul din care alegem estimările noastre îmbunătățite adăugând , și așa mai departe, în ordine. Vectorul estimat la iterația a -a se află în
Acum, folosind relația că
vedem că
Adică, spațiul pe care îl construim și care aproximează cel mai eficient soluția corectă este exact spațiul construit prin aplicarea succesivă a matricei pe Un subspațiu Krylov este spațiul generat de vectorii direcțiilor succesive de coborâre în gradient.
În final, reiterăm că nu am făcut nicio afirmație numerică despre scalarea acestei abordări și nici nu am discutat avantajul comparativ pentru matrici rare. Aceasta este menită doar să motiveze utilizarea metodelor subspațiului Krylov și să adauge un sens intuitiv pentru ele. Vom explora acum comportamentul acestor metode numeric.
Verifică-ți înțelegerea
Citește întrebarea de mai jos, gândește-te la răspuns, apoi apasă pe triunghi pentru a dezvălui soluția.
În fluxul de lucru de mai sus, am propus minimizarea normei-A a erorii. Ce alte cantități ai putea lua în considerare să minimizezi în căutarea stării fundamentale și a valorii sale proprii?
Răspuns:
S-ar putea imagina utilizarea vectorului rezidual în locul normei-A a erorii. Ar putea exista cazuri în care luarea în considerare a vectorului de eroare însuși este utilă.
2. Metode Krylov în computația clasică
În această secțiune implementăm iterațiile Arnoldi computațional, astfel încât să putem folosi un subspațiu Krylov pentru rezolvarea problemelor de valori proprii. Vom aplica mai întâi acest lucru pe un exemplu de mică scară, apoi vom examina cum se scalează timpul de calcul pe măsură ce dimensiunea matricei de interes crește. O idee cheie aici va fi că generarea vectorilor care acoperă spațiul Krylov va fi un contributor major la timpul total de calcul necesar. Memoria necesară va varia între metodele Krylov specifice. Dar constrângerile de memorie pot limita utilizarea metodelor Krylov tradiționale.
2.1 Exemplu simplu de mică scară
În procesul de creare a unui subspațiu Krylov, va trebui să ortonormalizăm vectorii din subspațiul nostru. Să definim o funcție care primește un vector deja stabilit din subspațiul nostru vknown (presupus a nu fi normalizat) și un vector candidat de adăugat în subspațiul nostru vnext, și face vnext ortogonal față de vknown și normalizat. Să definim în continuare o funcție care parcurge acest proces pentru toți vectorii stabiliți din subspațiul nostru Krylov, pentru a asigura un set complet ortonormal.
# vknown is some established vector in our subspace. vnext is one we wish to add,
# which must be orthogonal to vknown.
def orthog_pair(vknown, vnext):
vknown = vknown / np.sqrt(vknown.T @ vknown)
diffvec = vknown.T @ vnext * vknown
vnext = vnext - diffvec
return vnext
# v is the candidate vector to be added to our subspace. s is the existing subspace.
def orthoset(v, s):
v = v / np.sqrt(v.T @ v)
temp = v
for i in range(len(s)):
temp = orthog_pair(s[i], temp)
v = temp / np.sqrt(temp.T @ temp)
return v
Acum să definim o funcție care construiește un subspațiu Krylov din ce în ce mai mare, până când spațiul vectorilor Krylov acoperă întregul spațiu al matricei originale. Aceasta ne va permite să vedem cât de bine se potrivesc valorile proprii obținute prin metoda subspațiului Krylov cu valorile exacte, în funcție de dimensiunea subspațiului Krylov. Important, funcția noastră krylov_full_build returnează vectorii Krylov, hamiltonienele proiectate, valorile proprii și timpul necesar.
# Necessary imports and definitions to track time in microseconds
import time
def time_mus():
return int(time.time() * 1000000)
# This function constructs a Krylov subspace that spans the whole space of the original matrix.
# Input:
# v0 : initial vector
# matrix : original matrix to be diagonalized
# Output:
# ks : Krylov vectors
# Hs : projected Hamiltonians
# eigs : eigenvalues
# k_tot_times : time required for the operation
def krylov_full_build(v0, matrix):
t0 = time_mus()
b = v0 / np.sqrt(v0 @ v0.T)
A = matrix
ks = []
ks.append(b)
Hs = []
eigs = []
Hs.append(b.T @ A @ b)
eigs.append(np.array([b.T @ A @ b]))
k_tot_times = []
for j in range(len(A) - 1):
vec = A @ ks[j].T
ortho = orthoset(vec, ks)
ks.append(ortho)
ksarray = np.array(ks)
Hs.append(ksarray @ A @ ksarray.T)
eigs.append(np.linalg.eig(Hs[j + 1]).eigenvalues)
k_tot_times.append(time_mus() - t0)
# Return the Krylov vectors, the projected Hamiltonians, the eigenvalues,
# and the total time required.
return (ks, Hs, eigs, k_tot_times)
Vom testa aceasta pe o matrice care este totuși destul de mică, dar mai mare decât am vrea să calculăm manual.
# Define our small test matrix
test_matrix = np.array(
[
[4, -1, 0, 1, 0],
[-1, 4, -1, 2, 1],
[0, -1, 4, 3, 3],
[1, 2, 3, 4, 0],
[0, 1, 3, 0, 4],
]
)
# Give the test matrix and an initial guess as arguments in the function defined above.
# Calculate outputs.
test_ks, test_Hs, test_eigs, text_k_tot_times = krylov_full_build(
np.array([0.5, 0.5, 0, 0.5, 0.5]), test_matrix
)
Putem verifica funcțiile noastre asigurându-ne că în ultimul pas (când spațiul Krylov este întregul spațiu vectorial al matricei originale) valorile proprii din metoda Krylov se potrivesc exact cu cele din diagonalizarea numerică exactă:
print(np.linalg.eig(test_matrix).eigenvalues)
print(test_eigs[len(test_matrix) - 1])
[-1.36956923 8.43756009 2.9040308 5.34436028 4.68361806]
[-1.36956923 8.43756009 2.9040308 4.68361806 5.34436028]
Asta a funcționat. Desigur, ceea ce contează cu adevărat este cât de bună este aproximarea noastră în funcție de dimensiunea subspațiului Krylov. Deoarece suntem adesea interesați de găsirea stărilor fundamentale și a altor valori proprii minime (și din alte motive mai algebrice explicate mai jos), să examinăm estimarea noastră a celei mai mici valori proprii în funcție de dimensiunea subspațiului Krylov. Adică
def errors(matrix, krylov_eigs):
targ_min = min(np.linalg.eig(matrix).eigenvalues)
err = []
for i in range(len(matrix)):
err.append(min(krylov_eigs[i]) - targ_min)
return err
import matplotlib.pyplot as plt
krylov_error = errors(test_matrix, test_eigs)
plt.plot(krylov_error)
plt.axhline(y=0, color="red", linestyle="--") # Add dashed red line at y=0
plt.xlabel("Order of Krylov subspace") # Add x-axis label
plt.ylabel("Error in minimum eigenvalue") # Add y-axis label
plt.show()
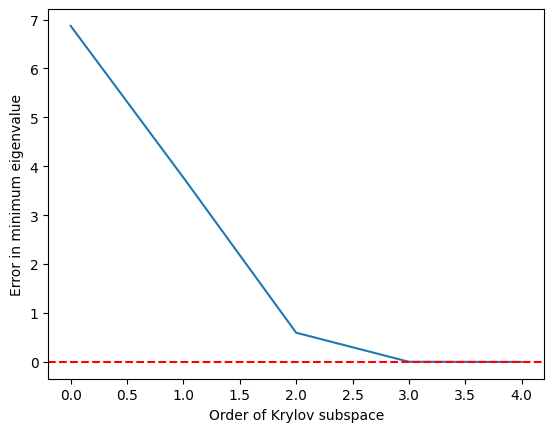
Observăm că valoarea proprie minimă este atinsă cu o precizie destul de bună odată ce subspațiul Krylov a crescut la și este perfectă la
2.2 Scalarea timpului cu dimensiunea matricei
Să ne convingem că metoda Krylov poate fi avantajoasă față de eigensolverele numerice exacte în felul următor:
- Construim matrice aleatoare (nu rare, nu aplicația ideală pentru KQD)
- Determinăm valorile proprii folosind două metode: direct cu NumPy și folosind un subspațiu Krylov.
- Alegem o limită pentru cât de precise trebuie să fie valorile noastre proprii, înainte de a accepta estimările Krylov.
- Comparăm timpul real necesar pentru a rezolva în aceste două moduri.
Avertismente: Așa cum vom discuta în detaliu mai jos, diagonalizarea cuantică Krylov este cel mai bine aplicată operatorilor ale căror reprezentări matriciale sunt rare și/sau pot fi scrise folosind un număr mic de grupuri de operatori Pauli care comutează. Matricele aleatoare pe care le folosim aici nu se potrivesc cu această descriere. Ele sunt utile doar pentru a sonda scala la care metodele Krylov clasice ar putea fi utile. În al doilea rând, folosind metoda Krylov, vom calcula valorile proprii folosind mai multe subspații de dimensiuni diferite. Vom raporta timpul necesar pentru subspațiul Krylov de dimensiune minimă care atinge precizia noastră necesară pentru valoarea proprie a stării fundamentale. Din nou, aceasta este puțin diferit de rezolvarea unei probleme care este intractabilă pentru eigensolverele exacte, deoarece folosim soluția exactă pentru a evalua dimensiunea necesară.
Începem prin generarea setului nostru de matrice aleatoare.
import numpy as np
# Set the random seed
np.random.seed(42)
# how many random matrices will we make
num_matrix = 200
matrices = []
for m in range(1, num_matrix):
matrices.append(np.random.rand(m, m))
Acum diagonalizăm fiecare matrice direct, folosind numpy. Calculăm timpul necesar pentru diagonalizare pentru o comparație ulterioară.
matrix_numpy_times = []
matrix_numpy_eigs = []
for mm in range(num_matrix - 1):
t0 = time_mus()
matrix_numpy_eigs.append(min(np.linalg.eig(matrices[mm]).eigenvalues))
matrix_numpy_times.append(time_mus() - t0)
plt.plot(matrix_numpy_times)
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()
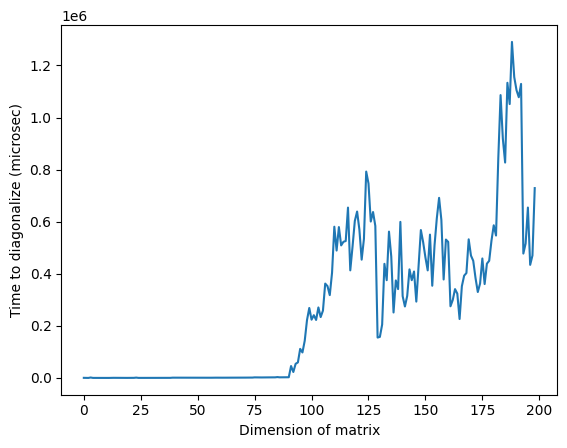
Observă că în imaginea de mai sus, timpul anormal de mare în jurul dimensiunii 125 poate fi datorat naturii aleatoare a matricelor sau implementării pe procesorul clasic folosit, dar nu este reproductibil. Rulând din nou codul vei obține un profil diferit cu vârfuri anormale diferite.
Acum, pentru fiecare matrice, vom construi un subspațiu Krylov și vom calcula valorile proprii în etape. La fiecare etapă, vom verifica dacă cea mai mică valoare proprie a fost obținută în cadrul erorii absolute specificate. Subspațiul care ne oferă prima dată valori proprii în cadrul erorii noastre specificate este subspațiul pentru care vom înregistra timpii de calcul. Executarea acestei celule poate dura câteva minute, în funcție de viteza procesorului. Nu ezita să sari peste evaluare sau să reduci dimensiunea maximă a matricelor diagonalizate. Examinarea rezultatelor precalculate este suficientă.
# Choose the absolute error you can tolerate, and make a list for tracking the Krylov subspace size
# at which that error is achieved.
abserr = 0.05
accept_subspace_size = []
# Lists to store total time spent on the Krylov method, and the subset of that time spent on
# diagonalizing the projected matrix.
matrix_krylov_tot_times = []
matrix_krylov_dim = []
# Step through all our random matrices
for mm in range(0, num_matrix - 1):
test_ks, test_Hs, test_eigs, test_k_tot_times = krylov_full_build(
np.ones(len(matrices[mm])), matrices[mm]
)
# We have not yet found a Krylov subspace that produces our minimum eigenvalue to
# within the required error.
found = 0
for j in range(0, len(matrices[mm]) - 1):
# If we still haven't found the desired subspace...
if found == 0:
# ...but if this one satisfies the requirement, then record everything
if (
abs((min(test_eigs[j]) - matrix_numpy_eigs[mm]) / matrix_numpy_eigs[mm])
< abserr
):
accept_subspace_size.append(j)
matrix_krylov_tot_times.append(test_k_tot_times[j])
matrix_krylov_dim.append(mm)
found = 1
Să reprezentăm grafic timpii obținuți pentru aceste două metode pentru comparație:
plt.plot(matrix_numpy_times, color="blue")
plt.plot(matrix_krylov_dim, matrix_krylov_tot_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()

Aceștia sunt timpii reali necesari, dar în scopul discuției, să netezim aceste curbe prin medierea peste câteva puncte/dimensiuni de matrice adiacente. Aceasta se face mai jos:
smooth_numpy_times = []
smooth_krylov_times = []
# Choose the number of adjacent points over which to average forward;
# the same will be used backward.
smooth_steps = 10
# We will do this smoothing for all points/matrix dimensions
for i in range(len(matrix_krylov_tot_times)):
# Ensure we don't exceed the boundaries of our lists
start = max(0, i - smooth_steps)
end = min(len(matrix_krylov_tot_times) - 1, i + smooth_steps)
# Dummy variables for accumulating an average over adjacent points. This is done for both Krylov
# and the NumPy calculations.
smooth_count = 0
smooth_numpy_sum = 0
smooth_krylov_sum = 0
for j in range(start, end):
smooth_numpy_sum = smooth_numpy_sum + matrix_numpy_times[j]
smooth_krylov_sum = smooth_krylov_sum + matrix_krylov_tot_times[j]
smooth_count = smooth_count + 1
# Appending the averaged adjacent values to our new smooth lists
smooth_numpy_times.append(smooth_numpy_sum / smooth_count)
smooth_krylov_times.append(smooth_krylov_sum / smooth_count)
plt.plot(smooth_numpy_times, color="blue")
plt.plot(smooth_krylov_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (smoothed, microsec)") # Add y-axis label
plt.show()

Observă că timpul necesar pentru construirea unui subspațiu Krylov depășește inițial timpul necesar pentru diagonalizarea completă cu numpy. Dar pe măsură ce dimensiunea matricei crește, metoda Krylov devine avantajoasă. Acest lucru este valabil chiar dacă reducem eroarea acceptabilă, dar avantajul apare la o dimensiune de matrice mai mare. Merită să analizăm mai îndeaproape.
Complexitatea temporală a diagonalizării numerice este (cu variații între algoritmi). Complexitatea temporală a generării unei baze ortonormale de vectori este de asemenea . Deci avantajul metodei Krylov nu este legat de utilizarea baze ortonormale, ci de utilizarea unei baze ortonormale particulare care selectează eficient valorile proprii de interes. Am văzut deja acest lucru din schița dovezii din prima secțiune a acestei lecții, și aceasta este critică pentru garanțiile de convergență ale metodelor Krylov. Să recapitulăm progresul nostru de până acum:
- Pentru matrice foarte mari, metoda subspațiului Krylov poate produce valori proprii aproximative în toleranțele necesare mai rapid decât algoritmii tradiționali de diagonalizare.
- Pentru astfel de matrice foarte mari, generarea unui subspațiu Krylov este cea mai consumatoare de timp parte a metodei subspațiului Krylov.
- Astfel, o modalitate eficientă de generare a unui subspațiu Krylov ar fi extrem de valoroasă. Acesta este locul în care calculatorul cuantic intră în scenă.
Verifică-ți înțelegerea
Citește întrebarea de mai jos, gândește-te la răspunsul tău, apoi apasă triunghiul pentru a dezvălui soluția.
Referă-te la graficul netezit al timpilor de diagonalizare față de dimensiunea matricei de mai sus.
(a) La aproximativ ce dimensiune de matrice a devenit metoda Krylov mai rapidă, conform acestui grafic?
(b) Ce aspecte ale calculului ar putea schimba dimensiunea la care metoda Krylov devine mai rapidă?
Răspuns:
(a) Răspunsurile pot varia dacă rulezi din nou calculul, dar metoda Krylov devine mai rapidă la aproximativ dimensiunea 80-85. (b) Există multe răspunsuri posibile. Unii factori importanți sunt precizia pe care o cerem și raritatea matricelor diagonalizate.
3. Krylov prin evoluție temporală
Tot ceea ce am descris până acum poate fi realizat clasic. Deci cum și când am folosi un calculator cuantic? Pentru matrice foarte mari, metoda Krylov poate necesita timpi lungi de calcul și cantități mari de memorie. Timpul necesar pentru operația matriceală a lui asupra lui crește în cel mai rău caz ca . Chiar și înmulțirea matricelor rare cu un vector (cazul tipic pentru rezolvitorii clasici de tip Krylov) are o complexitate temporală de ordinul . Aceasta se face pentru fiecare vector pe care dorim să îl avem în subspațiul nostru. Dimensiunea subspațiului nu este de obicei o fracție semnificativă din și crește adesea ca . Deci generarea tuturor vectorilor are un cost de în cel mai rău caz. Deși există și alți pași, precum ortonormalizarea, aceasta este scalarea dominantă de reținut.
Calculul cuantic ne permite să schimbăm ce atribute ale problemei determină scalarea timpului și resurselor necesare. În loc de dependența de dimensiunea matricei în toți termenii, vom vedea lucruri precum numărul de măsurători și numărul de termeni Pauli necomutatori care alcătuiesc Hamiltonianul. Hai să explorăm cum funcționează aceasta.
3.1 Evoluție temporală
Reține că operatorul care evoluează temporal o stare cuantică este (și este foarte obișnuit, mai ales în calculul cuantic, să se omită din notație). O modalitate de a înțelege și chiar de a realiza o astfel de funcție exponențială a unui operator este să privim dezvoltarea sa în serie Taylor. Observă că această operație aplicată unui vector inițial produce o sumă de termeni cu puteri crescătoare ale lui aplicate stării inițiale. Se pare că putem construi subspațiul Krylov pur și simplu evoluând temporal starea inițială!
Problema constă în realizarea evoluției temporale pe un calculator cuantic real. Mulți dintre termenii Hamiltonianului nu vor comuta între ei. Astfel, deși unii operatori exponențiali simpli precum corespund unor circuite simple, Hamiltonenii generali nu. Și deoarece conțin termeni necomutatori, nu putem descompune pur și simplu exponențiala într-un produs de exponențiale simple, așa cum putem face cu numerele.
Deci aceasta nu este trivial, dar este un proces bine studiat în calculul cuantic. Realizăm evoluția temporală pe calculatoare cuantice folosind un proces numit trotterizare, care în sine este un subiect bogat[10]. Dar la un nivel foarte înalt, prin împărțirea evoluției temporale în pași foarte mici, să zicem pași de dimensiune , limităm efectele necomutativității termenilor.
unde .
Să numim un subspațiu Krylov de ordinul r generat în contextul clasic folosind puteri directe ale lui H un „subspațiu Krylov prin puteri".
Acum generăm un spațiu similar folosind operatorul unitar de evoluție temporală ; îl vom numi „subspațiul Krylov unitar" . Subspațiul Krylov prin puteri pe care îl folosim clasic nu poate fi generat direct pe un calculator cuantic deoarece nu este un operator unitar. Se poate demonstra că utilizarea subspațiului Krylov unitar oferă garanții de convergență similare cu subspațiul Krylov prin puteri, și anume că eroarea stării fundamentale converge eficient atât timp cât starea inițială are suprapunere cu adevărata stare fundamentală care nu este exponențial de mică, și atât timp cât există un spațiu suficient între valorile proprii. Vezi Ref [1] pentru o discuție mai precisă despre convergență.
Aici, puterile lui devin diferiți pași temporali (a -a putere a lui reprezintă avansarea cu un timp ). Putem eticheta elementul subspațiului care a evoluat temporal pentru un timp total ca .
Putem proiecta Hamiltonianul H pe subspațiul Krylov unitar, . Cu alte cuvinte, calculăm fiecare element matriceal al lui în baza . Vom numi această matrice proiectată .
3.2 Cum se implementează pe un calculator cuantic
Elementele matriceale ale lui sunt date de valorile de așteptare , care pot fi estimate folosind calculatorul cuantic. Ține minte că poate fi scris ca o sumă de operatori Pauli pe diferiți qubiți și că nu toți operatorii Pauli pot fi măsurați simultan. Putem sorta termenii Pauli în grupuri de termeni comutatori și să îi măsurăm pe toți deodată. Dar este posibil să avem nevoie de multe astfel de grupuri pentru a acoperi toți termenii. Deci numărul de grupuri comutante distincte în care termenii pot fi partiționați, , devine important.
Aici este un șir Pauli de forma sau un set de astfel de șiruri Pauli care comută unele cu altele. Dat că putem scrie ca o astfel de sumă de operatori măsurabili, următoarele expresii pentru elementele matriceale ale lui pot fi realizate folosind primitivul Estimator din Qiskit Runtime.
Unde sunt vectorii spațiului Krylov unitar și sunt multiplii pasului temporal ales. Pe un calculator cuantic, calculul fiecărui element matriceal poate fi realizat cu orice algoritm care ne permite să obținem suprapunerea dintre stările cuantice. În această lecție ne vom concentra pe testul Hadamard. Dat că are dimensiunea , Hamiltonianul proiectat în subspațiu va avea dimensiunile . Cu suficient de mic (în general este suficient pentru a obține convergența estimărilor valorilor proprii) putem apoi să diagonalizăm cu ușurință clasic Hamiltonianul proiectat . Cu toate acestea, nu putem diagonaliza direct din cauza non-ortogonalității vectorilor spațiului Krylov. Va trebui să măsurăm suprapunerile lor și să construim o matrice
Aceasta ne permite să rezolvăm problema valorilor proprii într-un spațiu non-ortogonal (numită și problemă generalizată a valorilor proprii)
Se pot obține apoi estimări ale valorilor proprii și stărilor proprii ale lui uitându-ne la soluțiile acestei probleme generalizate a valorilor proprii. De exemplu, estimarea energiei stării fundamentale se obține luând cea mai mică valoare proprie și starea fundamentală din vectorul propriu corespunzător . Coeficienții din determină contribuția diferiților vectori care formează baza lui .
Problema generalizată a valorilor proprii
De ce nu putem pur și simplu diagonaliza ? Deoarece conține informații despre geometria bazei Krylov (care este non-ortogonală în toate cazurile în afara celor foarte speciale), prin sine nu descrie o proiecție a Hamiltonianului complet, astfel valorile sale proprii nu au nicio relație particulară cu cele ale Hamiltonianului complet — ar putea fi orice valori aleatorii. Rezolvarea problemei generalizate a valorilor proprii este necesară pentru a obține valorile proprii și vectorii proprii aproximativi corespunzători proiecției Hamiltonianului complet în spațiul Krylov.
Figura prezintă o reprezentare de circuit a testului Hadamard modificat, o metodă folosită pentru a calcula suprapunerea dintre diferite stări cuantice. Pentru fiecare element matriceal , se efectuează un test Hadamard între stările , . Aceasta este evidențiată în figură prin schema de culori pentru elementele matriceale și operațiile corespunzătoare , . Astfel, un set de teste Hadamard pentru toate combinațiile posibile de vectori ai spațiului Krylov este necesar pentru a calcula toate elementele matriceale ale Hamiltonianului proiectat . Firul de sus din circuitul testului Hadamard este un qubit auxiliar care este măsurat fie în baza X fie în baza Y; valoarea sa de așteptare determină valoarea suprapunerii dintre stări. Firul de jos reprezintă toți qubiții Hamiltonianului sistemului. Operația pregătește qubitul sistemului în starea condiționat de starea qubitului auxiliar (similar pentru ) și operația reprezintă descompunerea Pauli a Hamiltonianului sistemului . Implementarea acesteia pe un calculator cuantic este prezentată mai detaliat mai jos.
4. Diagonalizarea cuantică Krylov pe un calculator cuantic
Vom implementa acum diagonalizarea cuantică Krylov pe un calculator cuantic real. Să începem prin a importa câteva pachete utile.
import numpy as np
import scipy as sp
import matplotlib.pylab as plt
from typing import Union, List
import warnings
from qiskit.quantum_info import SparsePauliOp, Pauli
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit, QuantumRegister
from qiskit.circuit.library import PauliEvolutionGate
from qiskit.synthesis import LieTrotter
# from qiskit.providers.fake_provider import Fake20QV1
from qiskit_ibm_runtime import QiskitRuntimeService, EstimatorV2 as Estimator, Batch
import itertools as it
warnings.filterwarnings("ignore")
Definim mai jos funcția care rezolvă problema valorilor proprii generalizate pe care tocmai am explicat-o.
def solve_regularized_gen_eig(
h: np.ndarray,
s: np.ndarray,
threshold: float,
k: int = 1,
return_dimn: bool = False,
) -> Union[float, List[float]]:
"""
Method for solving the generalized eigenvalue problem with regularization
Args:
h (numpy.ndarray):
The effective representation of the matrix in our Krylov subspace
s (numpy.ndarray):
The matrix of overlaps between vectors of our Krylov subspace
threshold (float):
Cut-off value for the eigenvalue of s
k (int):
Number of eigenvalues to return
return_dimn (bool):
Whether to return the size of the regularized subspace
Returns:
lowest k-eigenvalue(s) that are the solution of the regularized generalized eigenvalue problem
"""
s_vals, s_vecs = sp.linalg.eigh(s)
s_vecs = s_vecs.T
good_vecs = np.array([vec for val, vec in zip(s_vals, s_vecs) if val > threshold])
h_reg = good_vecs.conj() @ h @ good_vecs.T
s_reg = good_vecs.conj() @ s @ good_vecs.T
if k == 1:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][0], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][0]
else:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][:k], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][:k]
Cel puțin în benchmarking-ul inițial, este util să cunoști o soluție clasică exactă pentru a verifica comportamentul de convergență. Funcția de mai jos calculează energia stării fundamentale a unui Hamiltonian, folosind ca argumente Hamiltonianul și numărul de qubiți.
def single_particle_gs(H_op, n_qubits):
"""
Find the ground state of the single particle(excitation) sector
"""
H_x = []
for p, coeff in H_op.to_list():
H_x.append(set([i for i, v in enumerate(Pauli(p).x) if v]))
H_z = []
for p, coeff in H_op.to_list():
H_z.append(set([i for i, v in enumerate(Pauli(p).z) if v]))
H_c = H_op.coeffs
print("n_sys_qubits", n_qubits)
n_exc = 1
sub_dimn = int(sp.special.comb(n_qubits + 1, n_exc))
print("n_exc", n_exc, ", subspace dimension", sub_dimn)
few_particle_H = np.zeros((sub_dimn, sub_dimn), dtype=complex)
sparse_vecs = [
set(vec) for vec in it.combinations(range(n_qubits + 1), r=n_exc)
] # list all of the possible sets of n_exc indices of 1s in n_exc-particle states
m = 0
for i, i_set in enumerate(sparse_vecs):
for j, j_set in enumerate(sparse_vecs):
m += 1
if len(i_set.symmetric_difference(j_set)) <= 2:
for p_x, p_z, coeff in zip(H_x, H_z, H_c):
if i_set.symmetric_difference(j_set) == p_x:
sgn = ((-1j) ** len(p_x.intersection(p_z))) * (
(-1) ** len(i_set.intersection(p_z))
)
else:
sgn = 0
few_particle_H[i, j] += sgn * coeff
gs_en = min(np.linalg.eigvalsh(few_particle_H))
print("single particle ground state energy: ", gs_en)
return gs_en
4.1 Pasul 1: Maparea problemei la circuite cuantice și operatori
Vom defini acum un Hamiltonian. Acesta este diferit de funcția de mai sus prin faptul că funcția de mai sus ia un Hamiltonian ca argument și returnează doar starea fundamentală, făcând acest lucru clasic. Hamiltonianul pe care îl definim aici determină nivelurile de energie ale tuturor stărilor proprii de energie, iar acest Hamiltonian poate fi construit folosind operatori Pauli și implementat pe un calculator cuantic.
Alegem un Hamiltonian corespunzător unui lanț de spini care pot avea orice orientare în spațiu, numit „lanț Heisenberg". Presupunem că al spin poate fi influențat de vecinii săi cei mai apropiați (spinii și ), dar nu de vecinii mai îndepărtați. Permitem, de asemenea, posibilitatea ca interacțiunea dintre spini să fie diferită atunci când spinii indică spre axe diferite. Această asimetrie apare uneori, de exemplu, datorită structurii rețelei cristaline în care sunt încorporați spinii.
# Define problem Hamiltonian.
n_qubits = 10
# coupling strength for XX, YY, and ZZ interactions
JX = 1
JY = 3
JZ = 2
# Define the Hamiltonian:
H_int = [["I"] * n_qubits for _ in range(3 * (n_qubits - 1))]
for i in range(n_qubits - 1):
H_int[i][i] = "Z"
H_int[i][i + 1] = "Z"
for i in range(n_qubits - 1):
H_int[n_qubits - 1 + i][i] = "X"
H_int[n_qubits - 1 + i][i + 1] = "X"
for i in range(n_qubits - 1):
H_int[2 * (n_qubits - 1) + i][i] = "Y"
H_int[2 * (n_qubits - 1) + i][i + 1] = "Y"
H_int = ["".join(term) for term in H_int]
H_tot = [
(term, JZ)
if term.count("Z") == 2
else (term, JY)
if term.count("Y") == 2
else (term, JX)
for term in H_int
]
# Get operator
H_op = SparsePauliOp.from_list(H_tot)
print(H_tot)
[('ZZIIIIIIII', 2), ('IZZIIIIIII', 2), ('IIZZIIIIII', 2), ('IIIZZIIIII', 2), ('IIIIZZIIII', 2), ('IIIIIZZIII', 2), ('IIIIIIZZII', 2), ('IIIIIIIZZI', 2), ('IIIIIIIIZZ', 2), ('XXIIIIIIII', 1), ('IXXIIIIIII', 1), ('IIXXIIIIII', 1), ('IIIXXIIIII', 1), ('IIIIXXIIII', 1), ('IIIIIXXIII', 1), ('IIIIIIXXII', 1), ('IIIIIIIXXI', 1), ('IIIIIIIIXX', 1), ('YYIIIIIIII', 3), ('IYYIIIIIII', 3), ('IIYYIIIIII', 3), ('IIIYYIIIII', 3), ('IIIIYYIIII', 3), ('IIIIIYYIII', 3), ('IIIIIIYYII', 3), ('IIIIIIIYYI', 3), ('IIIIIIIIYY', 3)]
Codul de mai jos restricționează Hamiltonianul la stările cu o singură particulă și folosește norma spectrală pentru a stabili o dimensiune bună pentru pasul de timp . Alegem euristic o valoare pentru pasul de timp dt (bazată pe limite superioare ale normei Hamiltonianului). Ref [9] a arătat că un pas de timp suficient de mic este , și că este preferabil, până la un punct, să subestimezi această valoare mai degrabă decât să o supraestimezi, deoarece supraestimarea poate permite contribuțiilor din stările de energie ridicată să corupă chiar și starea optimă din spațiul Krylov. Pe de altă parte, alegerea unui prea mic duce la un condiționare mai slabă a subspațiului Krylov, deoarece vectorii bazei Krylov diferă mai puțin de la un pas de timp la altul.
# Get Hamiltonian restricted to single-particle states
single_particle_H = np.zeros((n_qubits, n_qubits))
for i in range(n_qubits):
for j in range(i + 1):
for p, coeff in H_op.to_list():
p_x = Pauli(p).x
p_z = Pauli(p).z
if all(p_x[k] == ((i == k) + (j == k)) % 2 for k in range(n_qubits)):
sgn = ((-1j) ** sum(p_z[k] and p_x[k] for k in range(n_qubits))) * (
(-1) ** p_z[i]
)
else:
sgn = 0
single_particle_H[i, j] += sgn * coeff
for i in range(n_qubits):
for j in range(i + 1, n_qubits):
single_particle_H[i, j] = np.conj(single_particle_H[j, i])
# Set dt according to spectral norm
dt = np.pi / np.linalg.norm(single_particle_H, ord=2)
dt
np.float64(0.17453292519943295)
Să specificăm dimensiunea maximă Krylov pe care dorim să o folosim, deși vom verifica convergența la dimensiuni mai mici. Specificăm, de asemenea, numărul de pași Trotter de folosit în evoluția temporală. Pentru scopul acestei lecții, vom alege o dimensiune Krylov maximă de doar 4. Aceasta este destul de limitată în contextul aplicațiilor realiste, dar este suficientă pentru acest exemplu. Vom explora metode în lecțiile ulterioare care ne permit să scalăm și să proiectăm Hamiltonianele noastre pe subspații mai mari.
# Set parameters for quantum Krylov algorithm
krylov_dim = 4 # size of krylov subspace
num_trotter_steps = 4
dt_circ = dt / num_trotter_steps
Pregătirea stării
Alege o stare de referință care are un oarecare overlap cu starea fundamentală. Pentru acest Hamiltonian, folosim o stare cu o excitație în qubitul din mijloc ca stare de referință.
qc_state_prep = QuantumCircuit(n_qubits)
qc_state_prep.x(int(n_qubits / 2) + 1)
qc_state_prep.draw("mpl", scale=0.5)

Evoluția temporală
Putem realiza operatorul de evoluție temporală generat de un Hamiltonian dat: prin aproximarea Lie-Trotter. Pentru simplitate, folosim PauliEvolutionGate integrat în circuitul de evoluție temporală. Sintaxa generală pentru aceasta este aceasta.
t = Parameter("t")
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=t, synthesis=LieTrotter(reps=num_trotter_steps)
)
qr = QuantumRegister(n_qubits)
qc_evol = QuantumCircuit(qr)
qc_evol.append(evol_gate, qargs=qr)
<qiskit.circuit.instructionset.InstructionSet at 0x7ccaa4664250>
Vom folosi o versiune a acestuia mai jos în testul Hadamard, dar avansând cu pași de timp .
Testul Hadamard
Reamintim că dorim să calculăm elementele de matrice atât ale , cât și ale matricei Gram folosind testul Hadamard. Să revedim cum funcționează aceasta în acest context, concentrându-ne mai întâi pe construcția lui Procesul de ansamblu este prezentat grafic mai jos. Straturile colorate de blocuri de pregătire a stărilor servesc ca un memento că acest proces este efectuat pentru toate combinațiile de și din subspațiul nostru.
Stările sistemului la pașii indicați sunt:
Aici este un termen Pauli din descompunerea Hamiltonianului (de remarcat că nu poate fi o combinație liniară de mai mulți termeni Pauli care comută, deoarece aceasta nu ar fi unitară — gruparea este posibilă folosind o construcție diferită pe care o vom arăta ulterior) , sunt operații controlate care pregătesc vectorii , ai spațiului Krylov unitar, cu . Aplicarea măsurătorilor de și acestui circuit calculează părțile reală și, respectiv, imaginară ale elementelor de matrice de care avem nevoie.
Pornind de la Pasul 4 de mai sus, aplică poarta Hadamard la qubiți zeroth.
Apoi măsoară fie , fie .
Din identitatea . Similar, măsurarea lui dă
Adăugând acești pași la evoluția temporală pe care am configurat-o anterior, scriem următoarele.
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
## Create the time-evo op dagger circuit
evol_gate_d = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
evol_gate_d = evol_gate_d.inverse()
# Put pieces together
qc_reg = QuantumRegister(n_qubits)
qc_temp = QuantumCircuit(qc_reg)
qc_temp.compose(qc_state_prep, inplace=True)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate, qargs=qc_reg)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate_d, qargs=qc_reg)
qc_temp.compose(qc_state_prep.inverse(), inplace=True)
# Create controlled version of the circuit
controlled_U = qc_temp.to_gate().control(1)
# Create hadamard test circuit for real part
qr = QuantumRegister(n_qubits + 1)
qc_real = QuantumCircuit(qr)
qc_real.h(0)
qc_real.append(controlled_U, list(range(n_qubits + 1)))
qc_real.h(0)
print("Circuit for calculating the real part of the overlap in S via Hadamard test")
qc_real.draw("mpl", fold=-1, scale=0.5)
Circuit for calculating the real part of the overlap in S via Hadamard test

Am avertizat deja despre adâncimea implicată în circuitele Trotter. Efectuarea testului Hadamard în aceste condiții poate produce un circuit și mai adânc, mai ales odată ce descompunem la porțile native. Aceasta va crește și mai mult dacă luăm în considerare topologia dispozitivului. Deci, înainte de a folosi orice timp pe calculatorul cuantic, este o idee bună să verificăm adâncimea la 2 qubiți a circuitului nostru.
print(
"Number of layers of 2Q operations",
qc_real.decompose(reps=2).depth(lambda x: x[0].num_qubits == 2),
)
Number of layers of 2Q operations 14401
Un circuit de această adâncime nu poate returna rezultate utilizabile pe calculatoarele cuantice moderne. Dacă vrem să construim și avem nevoie de o metodă mai bună. Acesta este motivul pentru testul Hadamard eficient introdus mai jos.
4. 2 Pasul 2. Optimizarea circuitelor și operatorilor pentru hardware-ul țintă
Testul Hadamard eficient
Putem optimiza circuitele adânci pentru testul Hadamard pe care le-am obținut introducând câteva aproximări și bazându-ne pe unele ipoteze despre Hamiltonianul modelului. De exemplu, consideră următorul circuit pentru testul Hadamard:
Presupunem că putem calcula clasic , valoarea proprie a lui sub Hamiltonianul . Aceasta este satisfăcută atunci când Hamiltonianul păstrează simetria U(1). Deși aceasta poate părea o ipoteză puternică, există multe cazuri în care este sigur să presupunem că există o stare de vid (în acest caz se mapează la starea ) care nu este afectată de acțiunea Hamiltonianului. Acest lucru este valabil, de exemplu, pentru Hamiltonianele de chimie care descriu o moleculă stabilă (unde numărul de electroni este conservat). Dat că poarta pregătește starea de referință dorită , de exemplu, pentru a pregăti starea HF pentru chimie, ar fi un produs de NOT-uri cu un singur qubit, deci controlat este doar un produs de CNOT-uri. Atunci circuitul de mai sus implementează următoarea stare înainte de măsurare:
unde am folosit deplasarea de fază simulabilă clasic de la pasul 2 la 3. Prin urmare, valorile de așteptare sunt
Folosind aceste ipoteze, am reușit să scriem valorile de așteptare ale operatorilor de interes cu mai puține operații controlate. De fapt, trebuie să implementăm doar pregătirea controlată a stării și nu evoluțiile temporale controlate. Reformulând calculul nostru ca mai sus ne va permite să reducem considerabil adâncimea circuitelor rezultate.
De remarcat că, ca bonus, deoarece operatorul Pauli apare acum ca o măsurătoare la sfârșitul circuitului mai degrabă decât ca o poartă controlată la mijloc, el poate fi măsurat alături de alți operatori Pauli care comută ca în descompunerea dată mai sus.
Descompunerea operatorului de evoluție temporală cu descompunerea Trotter
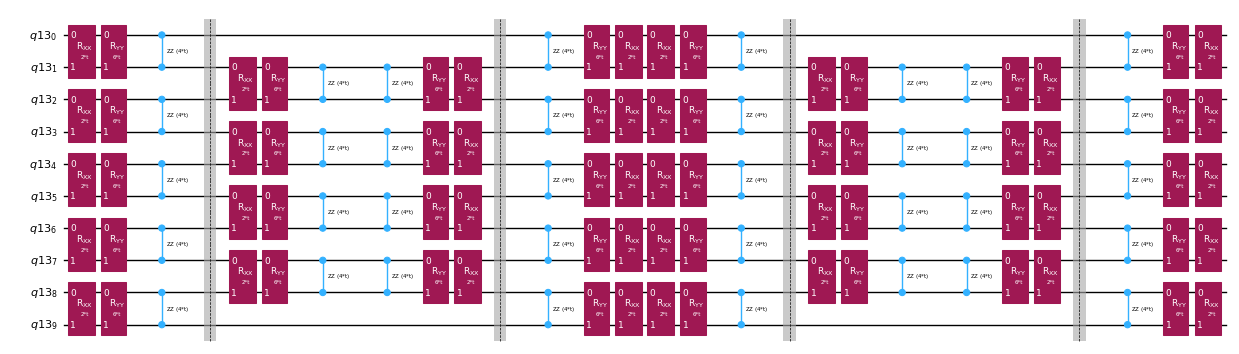
În loc să implementăm exact operatorul de evoluție temporală, putem folosi descompunerea Trotter pentru a implementa o aproximare a acestuia. Repetând de mai multe ori o descompunere Trotter de un anumit ordin, obținem o reducere suplimentară a erorii introduse de aproximare. În cele ce urmează, construim direct implementarea Trotter în cel mai eficient mod pentru graful de interacțiune al Hamiltonianului pe care îl considerăm (numai interacțiuni între cei mai apropiați vecini). În practică, inserăm rotații Pauli , , cu intensitățile de cuplaj , și și un unghi parametrizat , care corespund implementării aproximative a lui . Dată fiind diferența în definiția rotațiilor Pauli și evoluția temporală pe care încercăm să o implementăm, va trebui să folosim parametrul pentru a obține o evoluție temporală de . Mai mult, inversăm ordinea operațiilor pentru numărul impar de repetări ale pașilor Trotter, ceea ce este echivalent din punct de vedere funcțional, dar permite sinteza operațiilor adiacente într-un singur unitar . Aceasta dă un circuit mult mai puțin adânc față de ceea ce se obține folosind funcționalitatea generică PauliEvolutionGate().
t = Parameter("t")
# Create instruction for rotation about XX+YY-ZZ:
Rxyz_circ = QuantumCircuit(2)
Rxyz_circ.rxx(2 * JX * t, 0, 1)
Rxyz_circ.ryy(2 * JY * t, 0, 1)
Rxyz_circ.rzz(2 * JZ * t, 0, 1)
Rxyz_instr = Rxyz_circ.to_instruction(label="R J_x XX + J_y YY + J_z ZZ")
interaction_list = [
[[i, i + 1] for i in range(0, n_qubits - 1, 2)],
[[i, i + 1] for i in range(1, n_qubits - 1, 2)],
] # linear chain
qr = QuantumRegister(n_qubits)
trotter_step_circ = QuantumCircuit(qr)
for i, color in enumerate(interaction_list):
for interaction in color:
trotter_step_circ.append(Rxyz_instr, interaction)
if i < len(interaction_list) - 1:
trotter_step_circ.barrier()
reverse_trotter_step_circ = trotter_step_circ.reverse_ops()
qc_evol = QuantumCircuit(qr)
for step in range(num_trotter_steps):
if step % 2 == 0:
qc_evol = qc_evol.compose(trotter_step_circ)
else:
qc_evol = qc_evol.compose(reverse_trotter_step_circ)
qc_evol.decompose().draw("mpl", fold=-1, scale=0.5)
Pregătim din nou o stare inițială pentru acest test Hadamard eficient.
control = 0
excitation = int(n_qubits / 2) + 1
controlled_state_prep = QuantumCircuit(n_qubits + 1)
controlled_state_prep.cx(control, excitation)
controlled_state_prep.draw("mpl", fold=-1, scale=0.5)

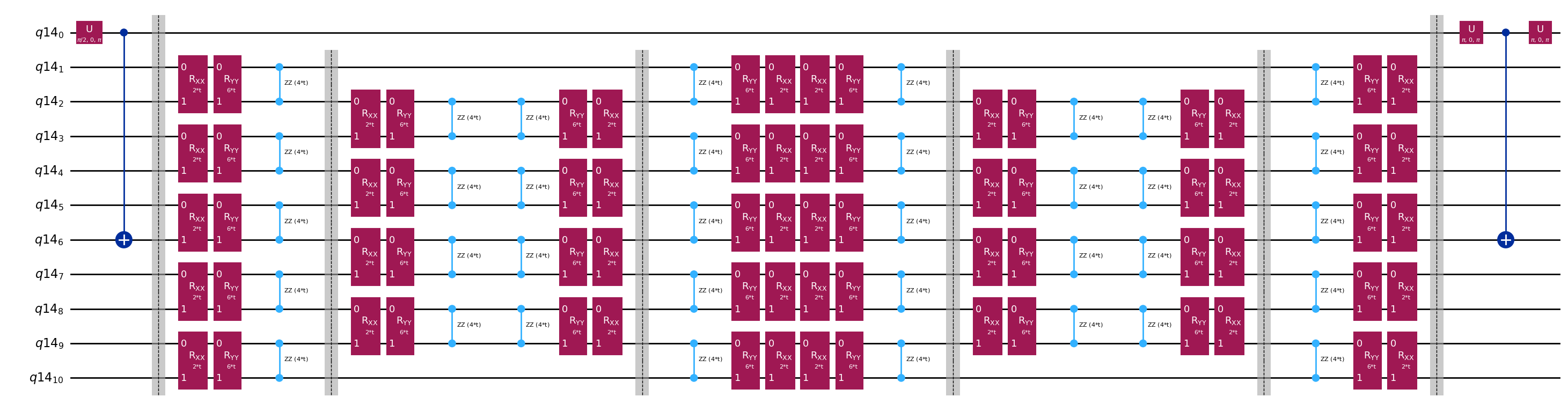
Circuite template pentru calcularea elementelor de matrice ale și prin testul Hadamard
Singura diferență dintre circuitele folosite în testul Hadamard va fi faza în operatorul de evoluție temporală și observabilele măsurate. Prin urmare, putem pregăti un circuit template care reprezintă circuitul generic pentru testul Hadamard, cu locuri-placeholder pentru porțile care depind de operatorul de evoluție temporală.
# Parameters for the template circuits
parameters = []
for idx in range(1, krylov_dim):
parameters.append(dt_circ * (idx))
# Create modified hadamard test circuit
qr = QuantumRegister(n_qubits + 1)
qc = QuantumCircuit(qr)
qc.h(0)
qc.compose(controlled_state_prep, list(range(n_qubits + 1)), inplace=True)
qc.barrier()
qc.compose(qc_evol, list(range(1, n_qubits + 1)), inplace=True)
qc.barrier()
qc.x(0)
qc.compose(controlled_state_prep.inverse(), list(range(n_qubits + 1)), inplace=True)
qc.x(0)
qc.decompose().draw("mpl", fold=-1)
print(
"The optimized circuit has 2Q gates depth: ",
qc.decompose().decompose().depth(lambda x: x[0].num_qubits == 2),
)
The optimized circuit has 2Q gates depth: 50
Această adâncime este substanțial redusă față de testul Hadamard original. Această adâncime este gestionabilă pe calculatoarele cuantice moderne, deși este totuși destul de mare. Va trebui să folosim o atenuare a erorilor de ultimă generație pentru a obține rezultate utile.
Selectează un backend pe care să rulăm calculul nostru Krylov cuantic, astfel încât să putem transpila circuitul nostru pentru a rula pe acel calculator cuantic.
# Use the least-busy backend or specify a quantum computer using the syntax commented out below.
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or you may choose a specify backend and channel if necessary for your workflow.
# service = QiskitRuntimeService(channel="ibm_quantum_platform")
# backend = service.backend("ibm_fez")
Acum transpilăm circuitele și operatorii noștri.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
basis_gates = list(target.operation_names)
pm = generate_preset_pass_manager(
optimization_level=3, backend=backend, basis_gates=basis_gates
)
qc_trans = pm.run(qc)
print(qc_trans.depth(lambda x: x[0].num_qubits == 2))
print(qc_trans.count_ops())
qc_trans.draw("mpl", fold=-1, idle_wires=False, scale=0.5)
36
OrderedDict([('rz', 410), ('sx', 361), ('cz', 156), ('x', 18), ('barrier', 6)])

După optimizare, adâncimea la doi qubiți a circuitului transpilat este redusă în continuare.
4.3 Pasul 3. Executarea folosind o primitivă Qiskit Runtime
Acum creăm PUB-uri pentru execuție cu Estimator.
# Define observables to measure for S
observable_S_real = "I" * (n_qubits) + "X"
observable_S_imag = "I" * (n_qubits) + "Y"
observable_op_real = SparsePauliOp(
observable_S_real
) # define a sparse pauli operator for the observable
observable_op_imag = SparsePauliOp(observable_S_imag)
layout = qc_trans.layout # get layout of transpiled circuit
observable_op_real = observable_op_real.apply_layout(
layout
) # apply physical layout to the observable
observable_op_imag = observable_op_imag.apply_layout(layout)
observable_S_real = (
observable_op_real.paulis.to_labels()
) # get the label of the physical observable
observable_S_imag = observable_op_imag.paulis.to_labels()
observables_S = [[observable_S_real], [observable_S_imag]]
# Define observables to measure for H
# Hamiltonian terms to measure
observable_list = []
for pauli, coeff in zip(H_op.paulis, H_op.coeffs):
# print(pauli)
observable_H_real = pauli[::-1].to_label() + "X"
observable_H_imag = pauli[::-1].to_label() + "Y"
observable_list.append([observable_H_real])
observable_list.append([observable_H_imag])
layout = qc_trans.layout
observable_trans_list = []
for observable in observable_list:
observable_op = SparsePauliOp(observable)
observable_op = observable_op.apply_layout(layout)
observable_trans_list.append([observable_op.paulis.to_labels()])
observables_H = observable_trans_list
# Define a sweep over parameter values
params = np.vstack(parameters).T
# Estimate the expectation value for all combinations of
# observables and parameter values, where the pub result will have
# shape (# observables, # parameter values).
pub = (qc_trans, observables_S + observables_H, params)
Circuitele pentru pot fi calculate clasic. Efectuăm aceasta înainte de a trece la cazul folosind un calculator cuantic.
from qiskit.quantum_info import StabilizerState, Pauli
qc_cliff = qc.assign_parameters({t: 0})
# Get expectation values from experiment
S_expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "X")
)
S_expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "Y")
)
# Get expectation values
S_expval = S_expval_real + 1j * S_expval_imag
H_expval = 0
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Get expectation values from experiment
expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "X")
)
expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "Y")
)
expval = expval_real + 1j * expval_imag
# Fill-in matrix elements
H_expval += coeff * expval
print(H_expval)
(10+0j)
Deși am reușit să reducem adâncimea porților cu ordine de mărime folosind testul Hadamard eficient, adâncimea este totuși suficientă pentru a necesita o atenuare a erorilor de ultimă generație. Mai jos, specificăm atributele atenuării utilizate. Toate metodele folosite sunt importante, dar merită menționată în mod special amplificarea probabilistică a erorilor (PEA). Această tehnică puternică vine cu o suprasolicitare cuantică considerabilă. Calculul efectuat aici poate dura 20 de minute sau mai mult pe un calculator cuantic real. Poți juca cu parametrii de mai jos pentru a crește sau reduce precizia și, în consecință, suprasolicitarea. Setările implicite de mai jos produc rezultate de înaltă fidelitate.
# Experiment options
num_randomizations = 300
num_randomizations_learning = 20
max_batch_circuits = 20
shots_per_randomization = 100
learning_pair_depths = [0, 4, 24]
noise_factors = [1, 1.3, 1.6]
# Base option formatting
options = {
# Builtin resilience settings for ZNE
"resilience": {
"measure_mitigation": True,
"zne_mitigation": True,
"zne": {"noise_factors": noise_factors},
# TREX noise learning configuration
"measure_noise_learning": {
"num_randomizations": num_randomizations_learning,
"shots_per_randomization": shots_per_randomization,
},
# PEA noise model configuration
"layer_noise_learning": {
"max_layers_to_learn": 10,
"layer_pair_depths": learning_pair_depths,
"shots_per_randomization": shots_per_randomization,
"num_randomizations": num_randomizations_learning,
},
},
# Randomization configuration
"twirling": {
"num_randomizations": num_randomizations,
"shots_per_randomization": shots_per_randomization,
"strategy": "all",
},
# Experimental settings for PEA method
"experimental": {
# # Just in case, disable any further qiskit transpilation not related to twirling / DD
# "skip_transpilation": True,
# Execution configuration
"execution": {
"max_pubs_per_batch_job": max_batch_circuits,
"fast_parametric_update": True,
},
# Error Mitigation configuration
"resilience": {
# ZNE Configuration
"zne": {
"amplifier": "pea",
"return_all_extrapolated": True,
"return_unextrapolated": True,
"extrapolated_noise_factors": [0] + noise_factors,
}
},
},
}
În final, executăm circuitele pentru și cu Estimator.
# This job required 17 minutes of QPU time to run on a Heron r2 processor. This is only an estimate.
# Your execution time may vary.
with Batch(backend=backend) as batch:
# Estimator
estimator = Estimator(mode=batch, options=options)
job = estimator.run([pub], precision=1)
4.4 Pasul 4. Post-procesarea și analiza rezultatelor
Ceea ce am obținut de la calculatorul cuantic sunt elementele individuale de matrice ale și grupurile Pauli care comută, care alcătuiesc elementele de matrice ale . Acești termeni trebuie combinați pentru a recupera matricele noastre, astfel încât să putem rezolva problema valorilor proprii generalizate.
# Store the outputs as 'results'.
results = job.result()[0]
Calcularea Hamiltonianului efectiv și a matricelor de overlap
Mai întâi calculăm faza acumulată de starea în timpul evoluției temporale necontrolate
prefactors = [
np.exp(-1j * sum([c for p, c in H_op.to_list() if "Z" in p]) * i * dt)
for i in range(1, krylov_dim)
]
Odată ce avem rezultatele execuțiilor circuitelor, putem post-procesa datele pentru a calcula elementele de matrice ale
# Assemble S, the overlap matrix of dimension D:
S_first_row = np.zeros(krylov_dim, dtype=complex)
S_first_row[0] = 1 + 0j
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[0][0][i] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[1][0][i] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
S_first_row[i + 1] += prefactors[i] * expval
S_first_row_list = S_first_row.tolist() # for saving purposes
S_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in it.product(range(krylov_dim), repeat=2):
if i >= j:
S_circ[j, i] = S_first_row[i - j]
else:
S_circ[j, i] = np.conj(S_first_row[j - i])
from sympy import Matrix
Matrix(S_circ)
Și elementele de matrice ale
import itertools
# Assemble S, the overlap matrix of dimension D:
H_first_row = np.zeros(krylov_dim, dtype=complex)
H_first_row[0] = H_expval
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[2 + 2 * obs_idx][0][
i
] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[2 + 2 * obs_idx + 1][0][
i
] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
H_first_row[i + 1] += prefactors[i] * coeff * expval
H_first_row_list = H_first_row.tolist()
H_eff_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in itertools.product(range(krylov_dim), repeat=2):
if i >= j:
H_eff_circ[j, i] = H_first_row[i - j]
else:
H_eff_circ[j, i] = np.conj(H_first_row[j - i])
from sympy import Matrix
Matrix(H_eff_circ)
În final, putem rezolva problema valorilor proprii generalizate pentru :
și obținem o estimare a energiei stării fundamentale
gnd_en_circ_est_list = []
for d in range(1, krylov_dim + 1):
# Solve generalized eigenvalue problem
gnd_en_circ_est = solve_regularized_gen_eig(
H_eff_circ[:d, :d], S_circ[:d, :d], threshold=1e-1
)
gnd_en_circ_est_list.append(gnd_en_circ_est)
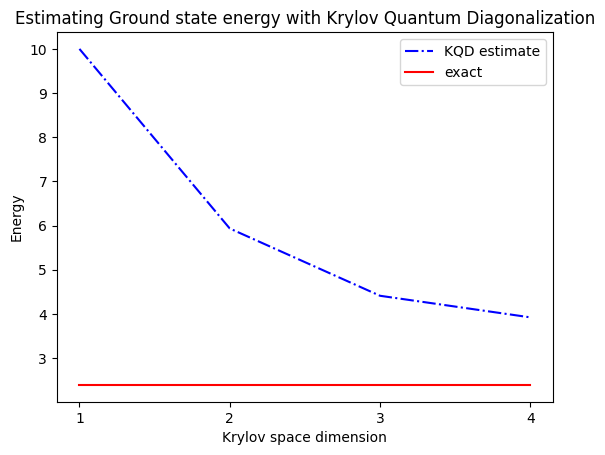
print("The estimated ground state energy is: ", gnd_en_circ_est)
The estimated ground state energy is: 10.0
The estimated ground state energy is: 5.933953916292923
The estimated ground state energy is: 4.4101773995740645
The estimated ground state energy is: 3.921288588521255
Pentru un sector cu o singură particulă, putem calcula eficient clasic starea fundamentală a acestui sector al Hamiltonianului
gs_en = single_particle_gs(H_op, n_qubits)
n_sys_qubits 10
n_exc 1 , subspace dimension 11
single particle ground state energy: 2.391547869638771
len(H_op)
27
plt.plot(
range(1, krylov_dim + 1),
gnd_en_circ_est_list,
color="blue",
linestyle="-.",
label="KQD estimate",
)
plt.plot(
range(1, krylov_dim + 1),
[gs_en] * krylov_dim,
color="red",
linestyle="-",
label="exact",
)
plt.xticks(range(1, krylov_dim + 1), range(1, krylov_dim + 1))
plt.legend()
plt.xlabel("Krylov space dimension")
plt.ylabel("Energy")
plt.title("Estimating Ground state energy with Krylov Quantum Diagonalization")
plt.show()
5. Discuție și extindere
Ca să recapitulăm, pornim de la o stare de referință, o evoluăm pentru diferite intervale de timp pentru a genera subspațiul Krylov unitar. Proiectăm Hamiltonianul nostru pe acel subspațiu. Estimăm, de asemenea, suprapunerile vectorilor subspațiului. În final, rezolvăm problema de valori proprii generalizată de dimensiune redusă, în mod clasic.
Să comparăm ce determină costurile de calcul ale utilizării tehnicii Krylov în mod clasic și în mod cuantic. Nu există analogii perfecte între abordările clasice și cele cuantice pentru toți pașii. Acest tabel reunește câteva scalări ale diferitelor etape pentru analiză.
Reamintim că Hamiltonianele au în general termeni care nu pot fi măsurați simultan (deoarece nu comutează unul cu celălalt). Grupăm termenii din Hamiltonian în grupuri de operatori Pauli comutativi care pot fi toți măsurați simultan, și este posibil să avem nevoie de multe astfel de grupuri pentru a acoperi toți termenii care nu comutează unul cu celălalt. Pentru a construi pe un calculator cuantic sunt necesare măsurători separate pentru fiecare grup de șiruri Pauli comutative din Hamiltonian, iar fiecare dintre acestea necesită multe măsurători. Trebuie să facem asta pentru elemente de matrice diferite, corespunzând combinații de factori diferiți de evoluție temporală. Există uneori modalități de a reduce acest lucru, dar în această tratare aproximativă, timpul necesar pentru aceasta scalează ca Elementele lui trebuie estimate, ceea ce scalează ca . În final, rezolvarea problemei de valori proprii generalizate în spațiul proiectat, în mod clasic, necesită
Vedem că diagonalizarea cuantică Krylov poate fi utilă în cazurile în care numărul de grupuri Pauli comutative din Hamiltonian este relativ mic. Aceste dependențe de scalare sugerează unele aplicații în care metoda Krylov poate fi utilă, și altele în care probabil nu va fi. Unele Hamiltoniene au o complexitate ridicată când sunt mapate pe qubiți, implicând mulți șiruri Pauli necomutative care nu pot fi ușor partiționați într-un număr mic de grupuri comutative. Acest lucru este adesea adevărat pentru problemele de chimie cuantică, de exemplu. Această complexitate prezintă două provocări principale pentru calculatoarele cuantice din etapa actuală:
- Estimarea fiecărui element al lui devine costisitoare din punct de vedere computațional din cauza numărului mare de termeni.
- Circuitele Trotter necesare devin prohibitiv de adânci.
Ambele puncte de mai sus vor fi mai puțin problematice când calculatoarele cuantice ating toleranța la erori, dar trebuie luate în considerare pe termen scurt. Chiar și sistemele cu mapări „mai simple" decât cele din chimia cuantică pot suferi de aceleași impedimente, dacă Hamiltonienele au prea mulți termeni necomutativi. Metoda Krylov este cel mai utilă acolo unde Hamiltonianul poate fi partiționat în relativ puține grupuri Pauli comutative și unde este ușor de implementat în circuite Trotter. Ambele condiții sunt satisfăcute, de exemplu, pentru multe modele pe rețea de interes în fizică. KQD este deosebit de util dacă se știe foarte puțin despre starea fundamentală. Acest lucru rezultă din garanțiile sale inerente de convergență și din aplicabilitatea sa în scenariile în care metodele alternative sunt inoperabile din cauza cunoștințelor insuficiente despre starea fundamentală.
Deși KQD este un instrument puternic, aspectele consumatoare de timp ale protocolului, în special estimarea fiecărui element al Hamiltonianului proiectat și suprapunerea stărilor Krylov, reprezintă oportunități de îmbunătățire. O abordare alternativă implică valorificarea metodelor Krylov în conjuncție cu metodele bazate pe eșantionare, care fac obiectul lecției următoare.
6. Anexe
Anexa I: Subspațiul Krylov din evoluții în timp real
Spațiul Krylov unitar este definit ca
pentru un pas de timp pe care îl vom determina mai târziu. Presupunem temporar că este par: atunci definim . Observăm că atunci când proiectăm Hamiltonianul în spațiul Krylov de mai sus, acesta este indistinct față de spațiul Krylov
adică, unde toate evoluțiile temporale sunt deplasate înapoi cu pași de timp. Motivul pentru care este indistinct este că elementele de matrice
sunt invariante față de deplasările globale ale timpului de evoluție, deoarece evoluțiile temporale comutează cu Hamiltonianul. Pentru impar, putem folosi analiza pentru .
Vrem să arătăm că undeva în acest spațiu Krylov există garantat o stare de energie joasă. Facem asta prin intermediul următorului rezultat, derivat din Teorema 3.1 din [3]:
Afirmația 1: există o funcție astfel încât pentru energii în intervalul spectral al Hamiltonianului (adică, între energia stării fundamentale și energia maximă)...
- pentru toate valorile lui care se află la distanță față de , adică este suprimată exponențial
- este o combinație liniară de pentru
Oferim o demonstrație mai jos, dar aceasta poate fi omisă în siguranță dacă nu dorești să înțelegi argumentul complet și riguros. Deocamdată ne concentrăm pe implicațiile afirmației de mai sus. Prin proprietatea 3 de mai sus, putem vedea că spațiul Krylov deplasat de mai sus conține starea . Aceasta este starea noastră de energie joasă. Pentru a înțelege de ce, scriem în baza proprie a energiei:
unde este starea proprie a energiei de rang k și este amplitudinea sa în starea inițială . Exprimată în acești termeni, este dată de
folosind faptul că putem înlocui cu când acționează pe starea proprie . Eroarea de energie a acestei stări este deci
Pentru a transforma aceasta într-o margine superioară mai ușor de înțeles, separăm mai întâi suma din numărător în termeni cu și termeni cu :
Putem margini superior primul termen prin ,
unde primul pas urmează deoarece pentru fiecare din sumă, iar al doilea pas urmează deoarece suma din numărător este un subset al sumei din numitor. Pentru al doilea termen, mai întâi marginim inferior numitorul prin , deoarece : adunând totul înapoi, obținem
Pentru a simplifica ce rămâne, observăm că pentru toți acești , prin definiția lui știm că . Marginind superior suplimentar și marginind superior obținem
Aceasta se aplică pentru orice , deci dacă setăm egal cu eroarea noastră țintă, atunci marginea de eroare de mai sus converge spre aceea exponențial cu dimensiunea Krylov . De asemenea, observăm că dacă atunci termenul dispare complet din marginea de mai sus.
Pentru a finaliza argumentul, notăm mai întâi că cele de mai sus reprezintă doar eroarea de energie a stării particulare , nu eroarea de energie a stării de energie minimă din spațiul Krylov. Cu toate acestea, prin principiul variațional (Rayleigh-Ritz), eroarea de energie a stării de energie minimă din spațiul Krylov este marginită superior de eroarea de energie a oricărei stări din spațiul Krylov, deci cele de mai sus reprezintă și o margine superioară pentru eroarea de energie a stării de energie minimă, adică rezultatul algoritmului de diagonalizare cuantică Krylov.
O analiză similară cu cea de mai sus poate fi realizată care ține seama suplimentar de zgomot și de procedura de pragare discutată în notebook. Vezi [2] și [4] pentru această analiză.
Anexa II: demonstrația Afirmației 1
Următoarele sunt derivate în mare parte din [3], Teorema 3.1: fie și fie spațiul polinoamelor reziduale (polinoame a căror valoare în 0 este 1) de grad cel mult . Soluția pentru
este
iar valoarea minimă corespunzătoare este
Vrem să convertim aceasta într-o funcție care poate fi exprimată în mod natural în termeni de exponențiale complexe, deoarece acestea sunt evoluțiile în timp real care generează spațiul Krylov cuantic. Pentru a face asta, este convenabil să introducem următoarea transformare a energiilor din intervalul spectral al Hamiltonianului în numere din intervalul : definim
unde este un pas de timp astfel încât . Observăm că și că crește pe măsură ce se îndepărtează de .
Acum folosind polinomul cu parametrii a, b, d setați la , , și d = int(r/2), definim funcția:
unde este energia stării fundamentale. Putem vedea prin inserarea că este un polinom trigonometric de grad , adică o combinație liniară de pentru . Mai mult, din definiția lui de mai sus avem că și pentru orice din intervalul spectral astfel încât avem
Referințe:
[1] https://arxiv.org/abs/2407.14431
[2] https://arxiv.org/abs/1811.09025
[3] https://people.math.ethz.ch/~mhg/pub/biksm.pdf
[4] https://academic.oup.com/book/36426
[5] https://en.wikipedia.org/wiki/Krylov_subspace
[6] Krylov Subspace Methods: Principles and Analysis, Jörg Liesen, Zdenek Strakos https://academic.oup.com/book/36426
[7] Iterative Methods for Sparse Linear Systems" by Yousef Saad
[8] "MINRES-QLP: A Krylov Subspace Method for Indefinite or Singular Symmetric Systems" by Sou-Cheng Choi, Christopher Paige, and Michael Saunders (https://epubs.siam.org/doi/10.1137/100787921)
[9] Ethan N. Epperly, Lin Lin, and Yuji Nakatsukasa. "A theory of quantum subspace diagonalization". SIAM Journal on Matrix Analysis and Applications 43, 1263–1290 (2022).